



Banner, нужно ее отправить и потом принять, как-то сложить, посортировать. Что в этот момент делать харкордный плюсовик в 2010 году? К сожалению, он делает memcpy. Если вы не знаете C++, там есть вектор, это последовательный набор структур в памяти. Если у вас баннер — это плоская структура, то есть просто кусок памяти, в котором они лежат. Давайте возьмем этот кусок памяти, вызовем base64.encode и отправим по сети, а там decode сделаем.
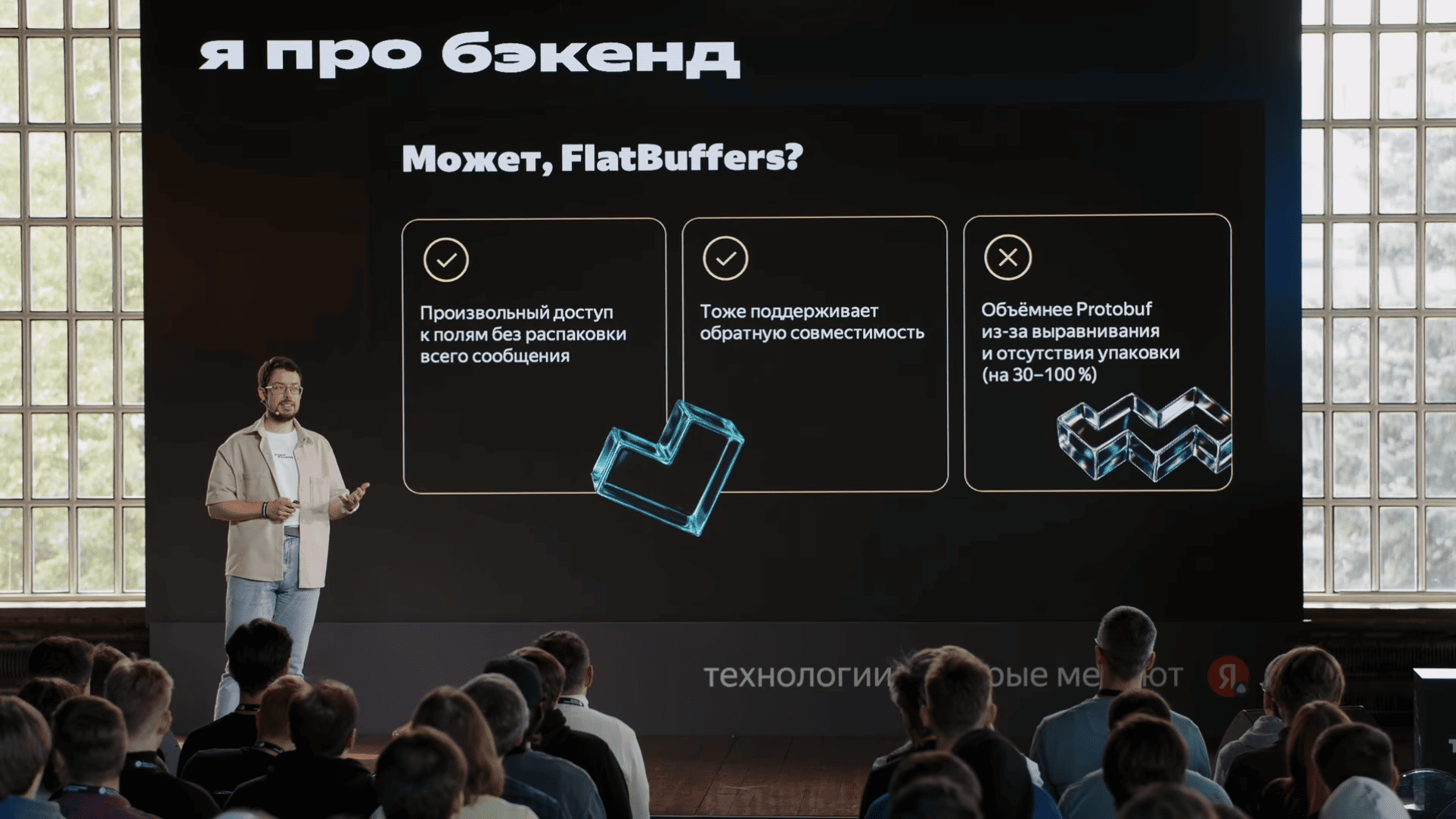
message под каждую структурку, сериализуем, десериализум. Что же может пойти не так? Смотрим на флеймграфы, и десятки процентов CPU-тайма тратятся на эту сериализацию и десериализацию. Вспоминаем наши масштабы, сотни тысяч CPU жжётся просто непонятно на что — на перекладывание туда-сюда этих байтиков.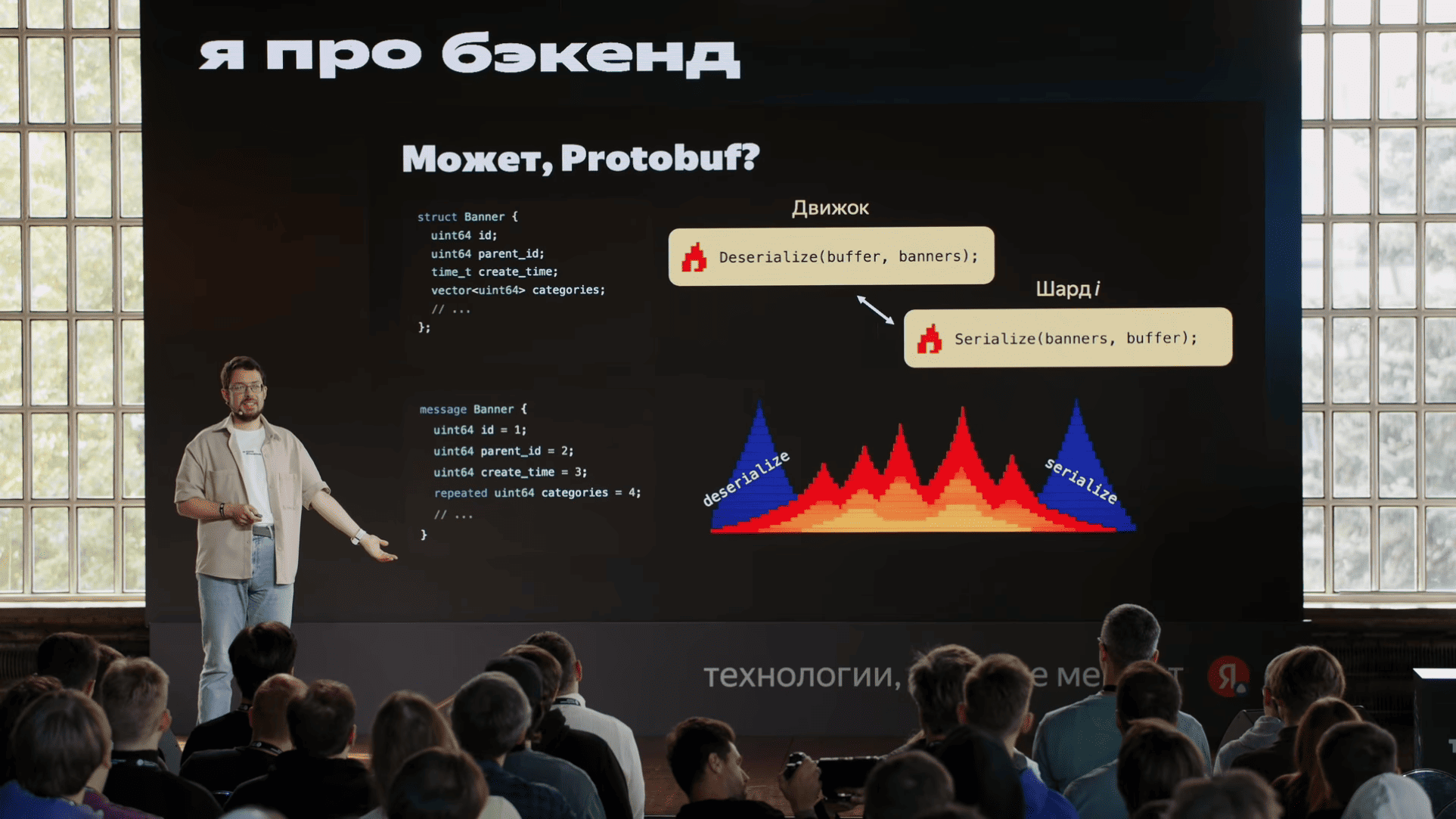



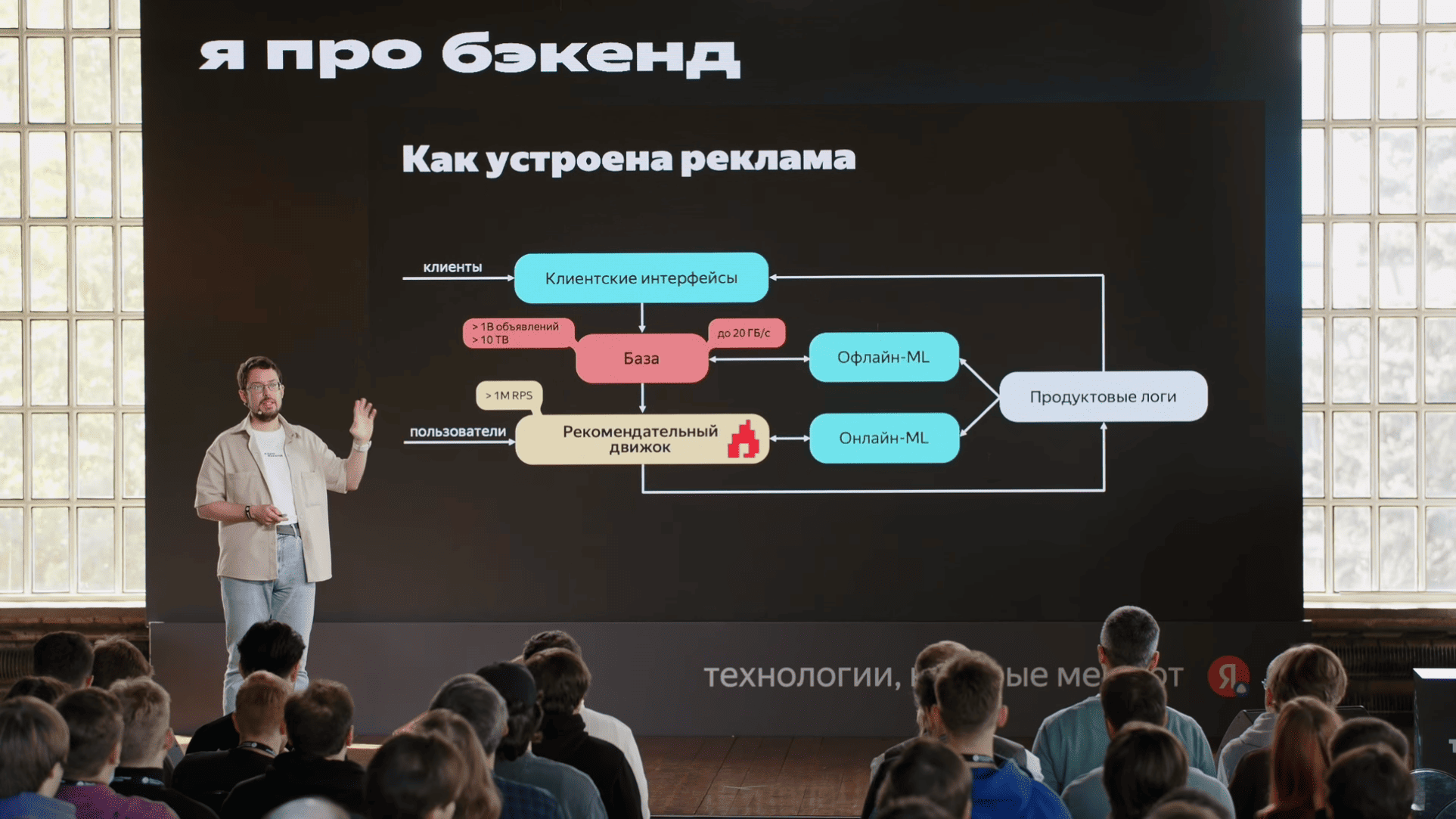
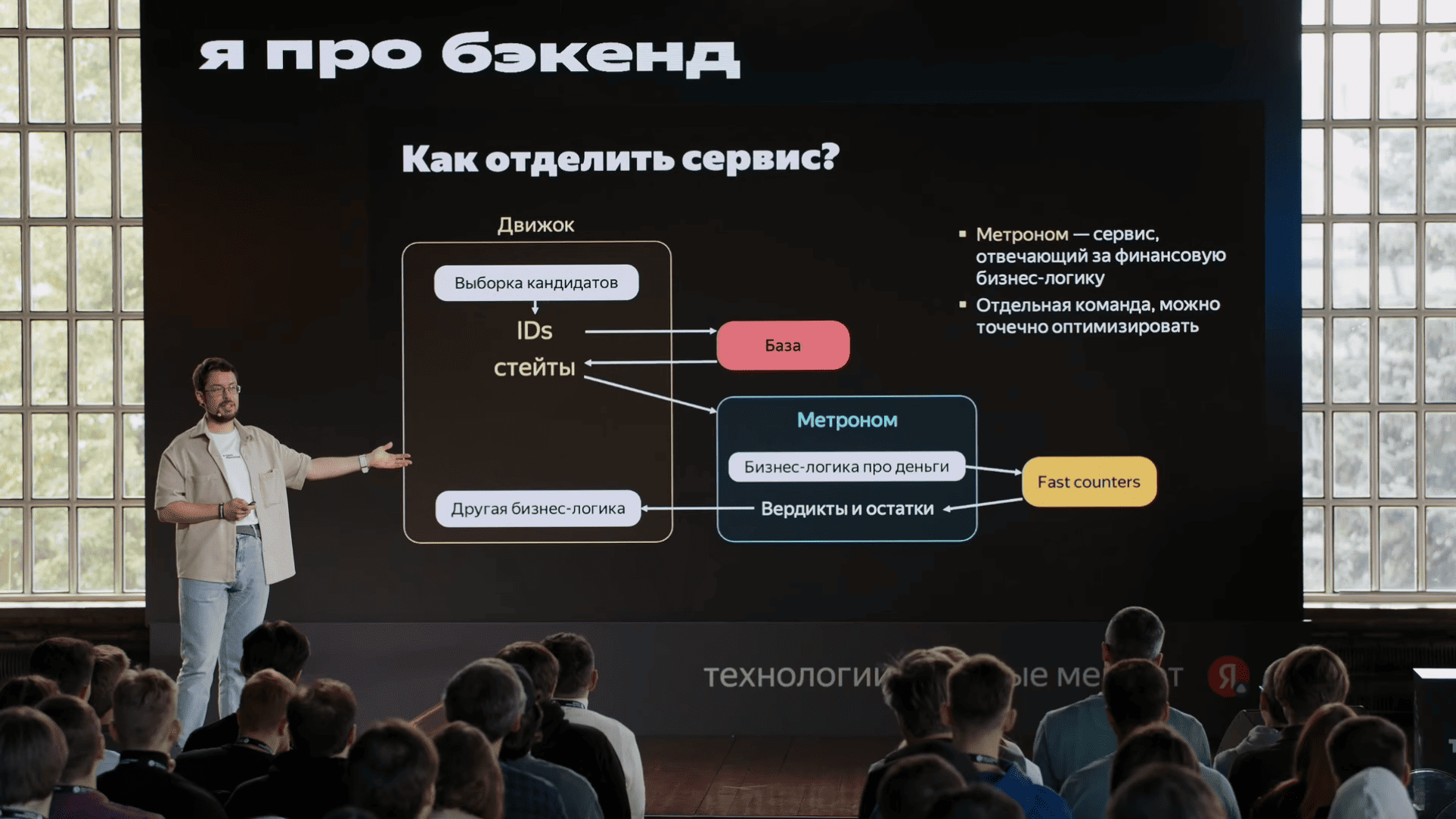
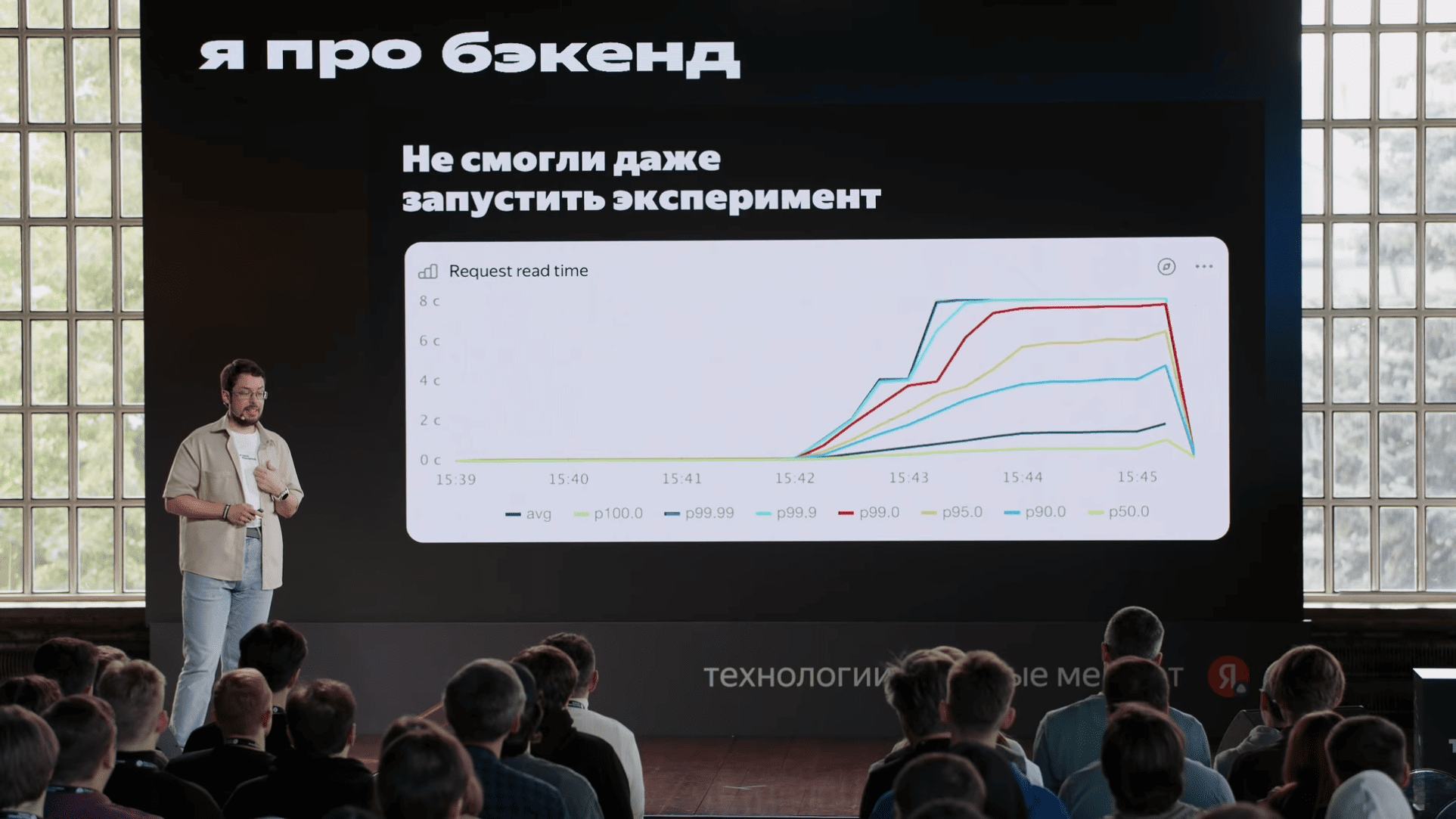
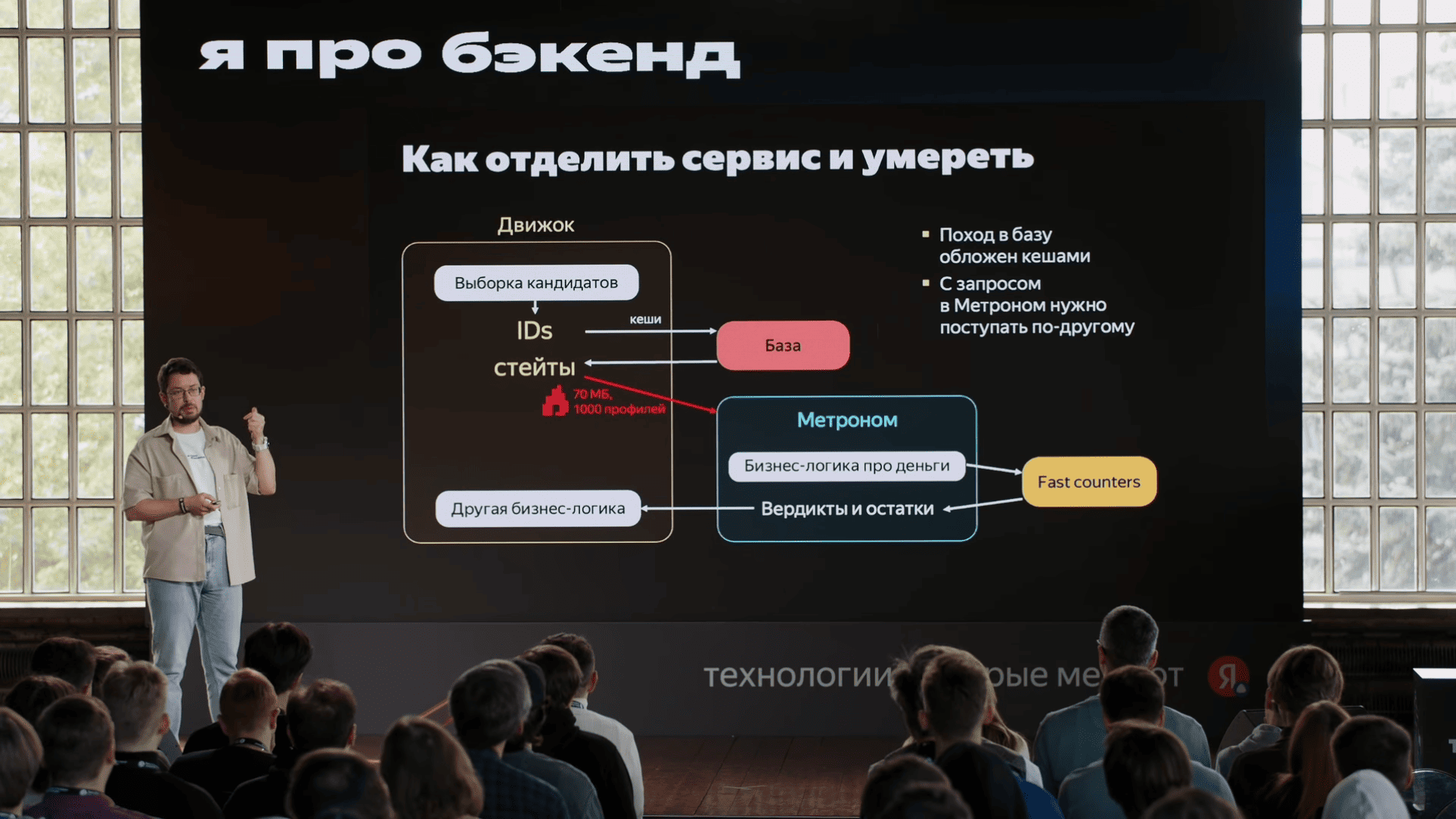
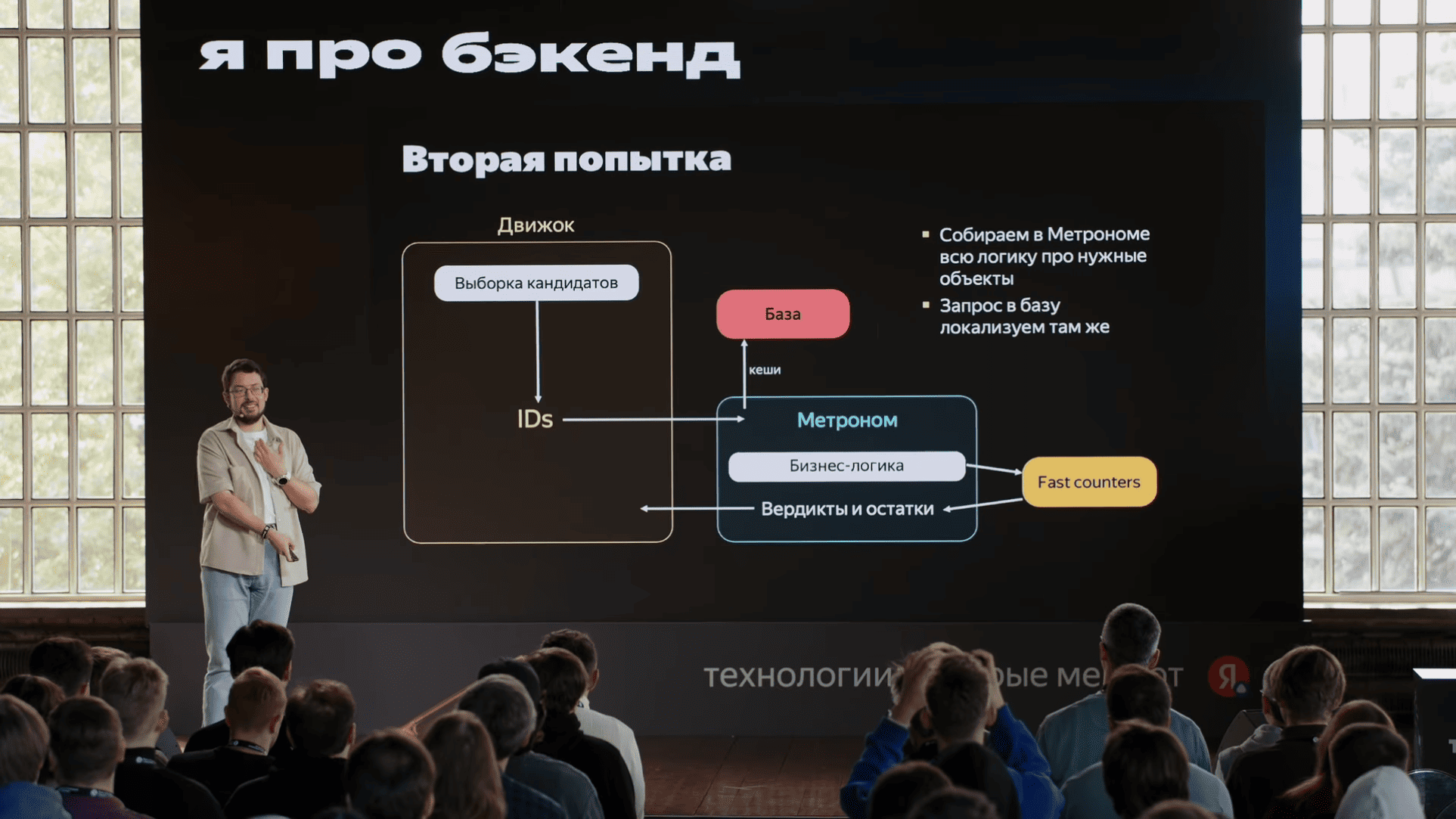
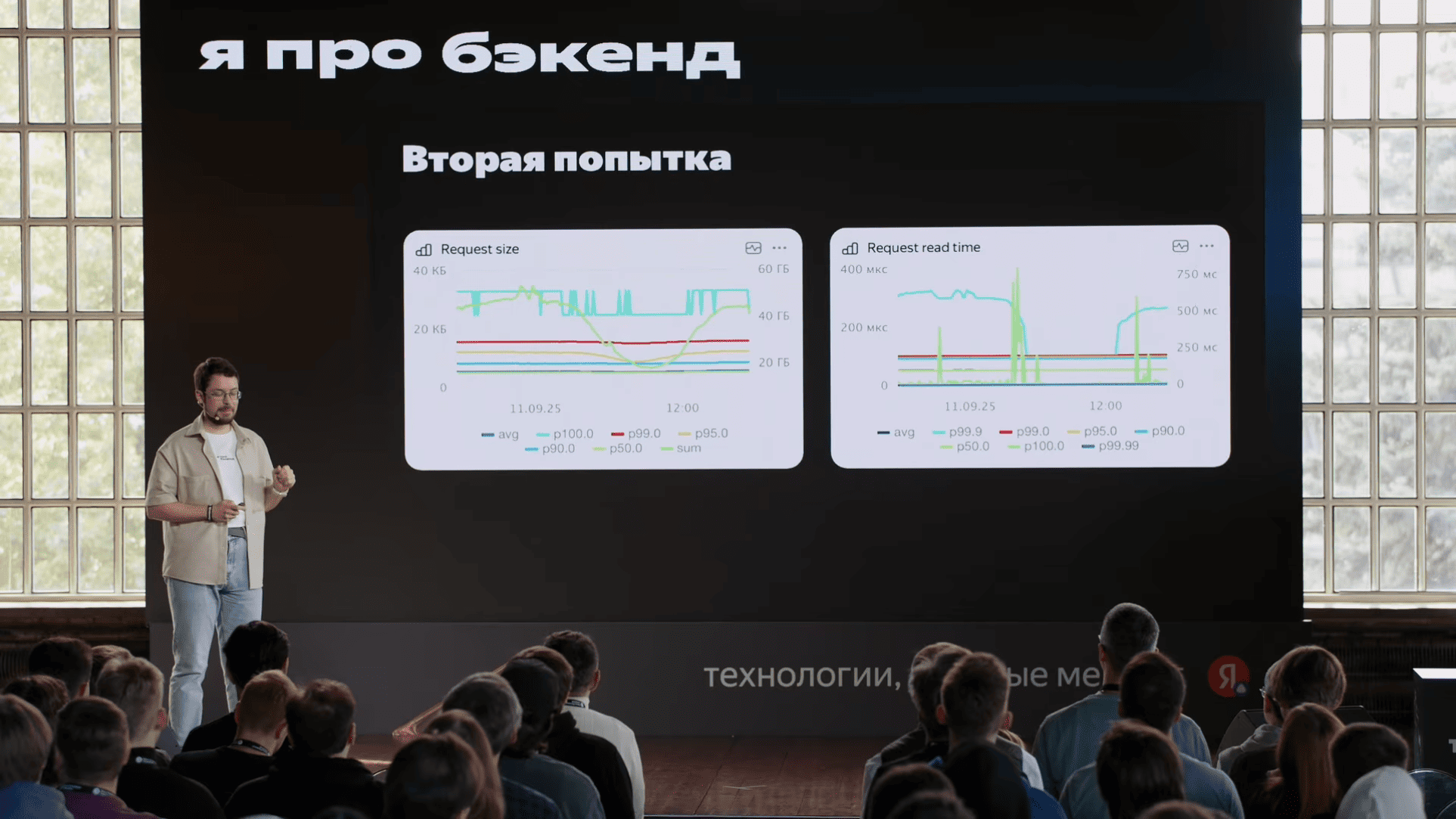
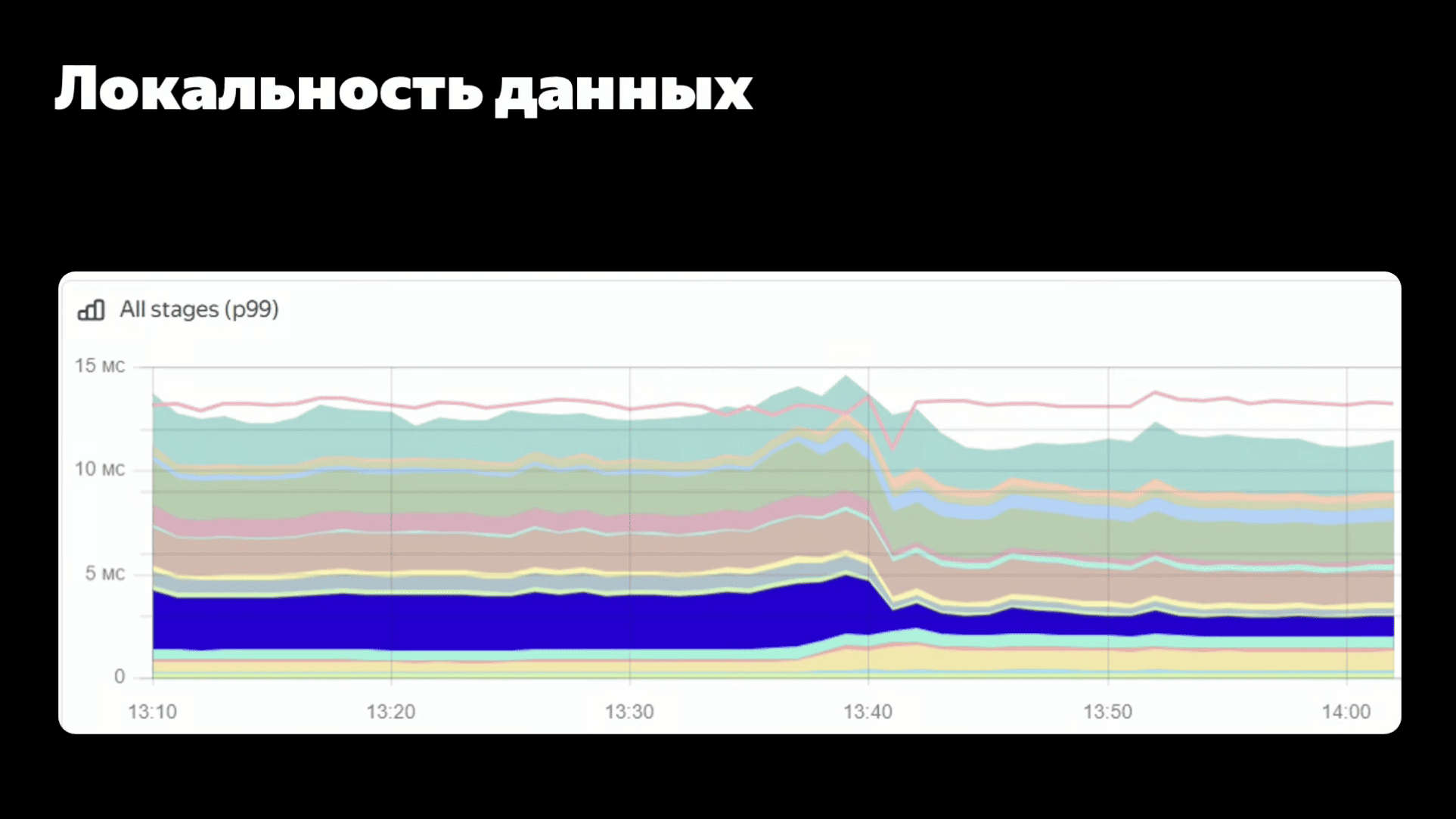
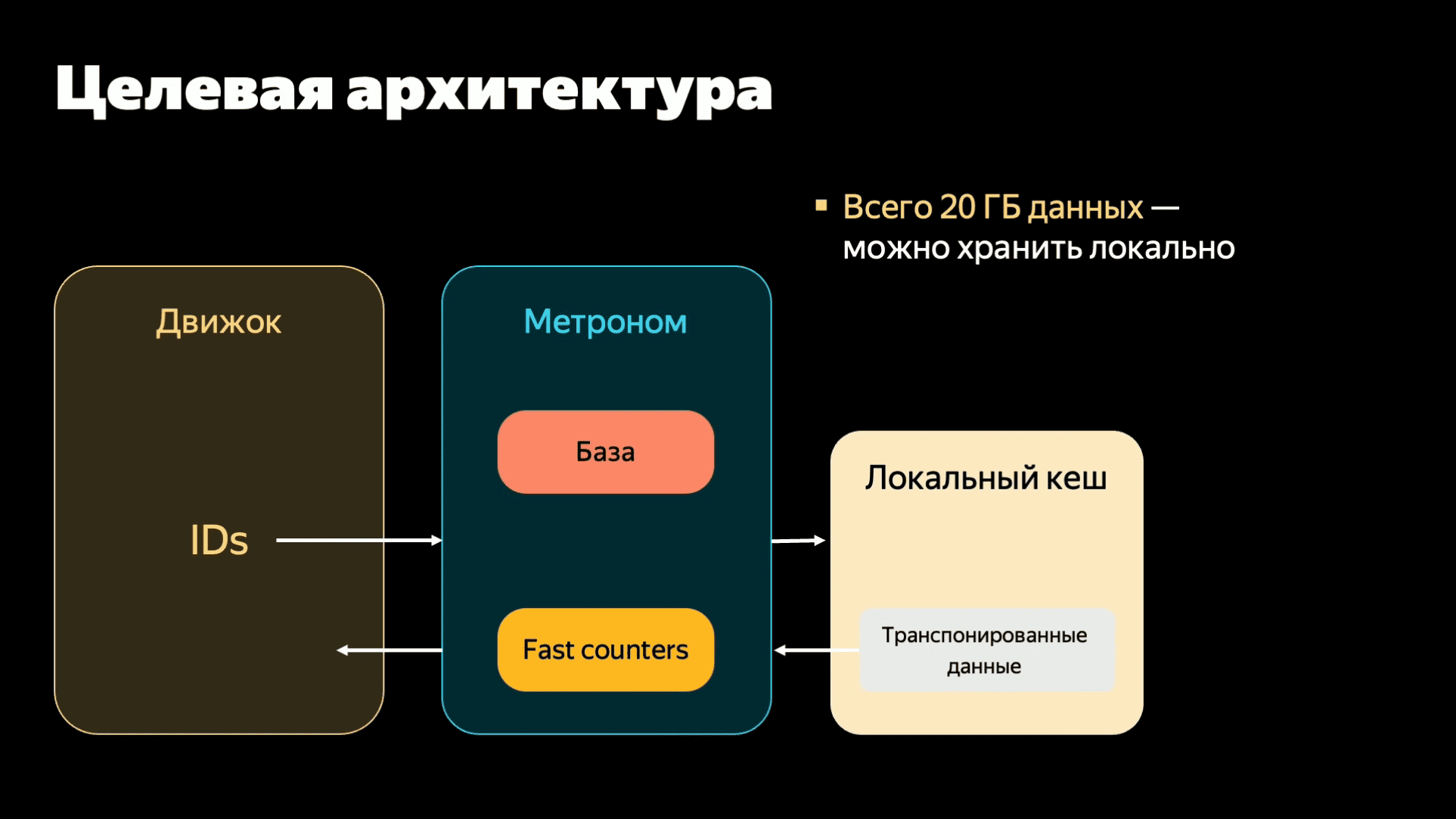
unordered_map, небольшой словарь "рекламная компания → сколько денег осталось" c максимально актуальными данными. Туда прямо HTTP-запросами эти данные слались. Мы, когда смотрели на флеймграфы, мы увидели, что запрос в этот сервис и парсинг ответа этого сервиса сильно отличаются с точки зрения производительности. Хотя запрос и ответ очень близки друг к другу по размерам, парсинг ответа был в пять раз дольше, чем формирование запроса. И это уже наводит на определенные мысли, что что-то у нас не так, и кажется, пока мы ждали ответа этого сервиса, пока было переключение контекста, у нас кэши все вымылись. Вымылись кэши с данными, вымылись кэши с кодом. Поскольку сервис большой, кэши по коду тоже имеет значение. Еще важно, что этим занимался отдельная команда, которая хотела отдельный алгоритм развивать. Короче, надо брать и выделить в микросервис.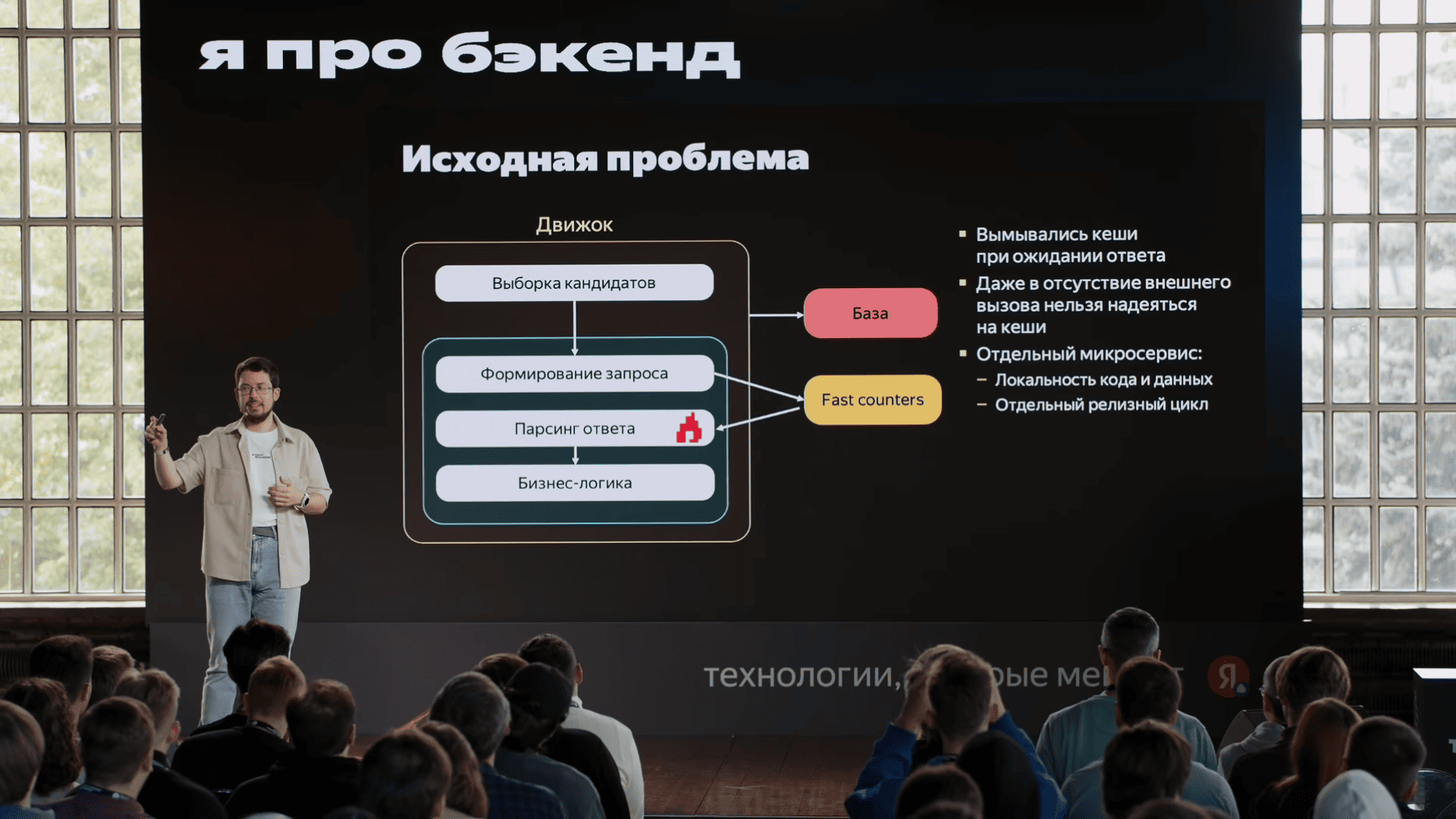


Мне понравился подход с микросервисами, что не микросервисы ради микросервисов, а именно выделено то, что нужно, потому что я постоянно говорю про накладные расходы. Про YaFF: очень хочется его увидеть, но я так понял, что это только для плюсов, да, у вас сделано?
Сделано только для плюсов, но как бы опенсорс тем и хорош, что...
Поэтому хочется увидеть, чтобы сделать свой вариант, например, для...
Ага, так, обсудим в кулуарах на кофе-брейке, окей.
--
В Директе сейчас можно нейронкой параметры задавать и не указывать вручную. Делали ли какие-то замеры, насколько эффективно рекламная компания работает, когда опытный специалист сам накидывает ключевые слова и остальные параметры, и когда это делает нейронка. То есть всё-таки можно рекомендовать людям, чтобы не заморачивались и пользовались автоматизацией?
Мы очень любим проводить эксперименты, и в целом, когда мы видим, что мы взяли какую-то ML-модель, которая как-то управляет параметрами, она почти всегда работает лучше, и в среднем точно работает лучше. Но при этом ты же не можешь в своем продукте сказать: "вот у вас был звездолет, вы могли им управлять как хотите, но там вообще-то сидят специалисты по маркетингу, крутые люди с образованием, как бы". И отнять в них 100 ручек — это довольно стремно. Поэтому там есть некоторые компромиссы всегда.
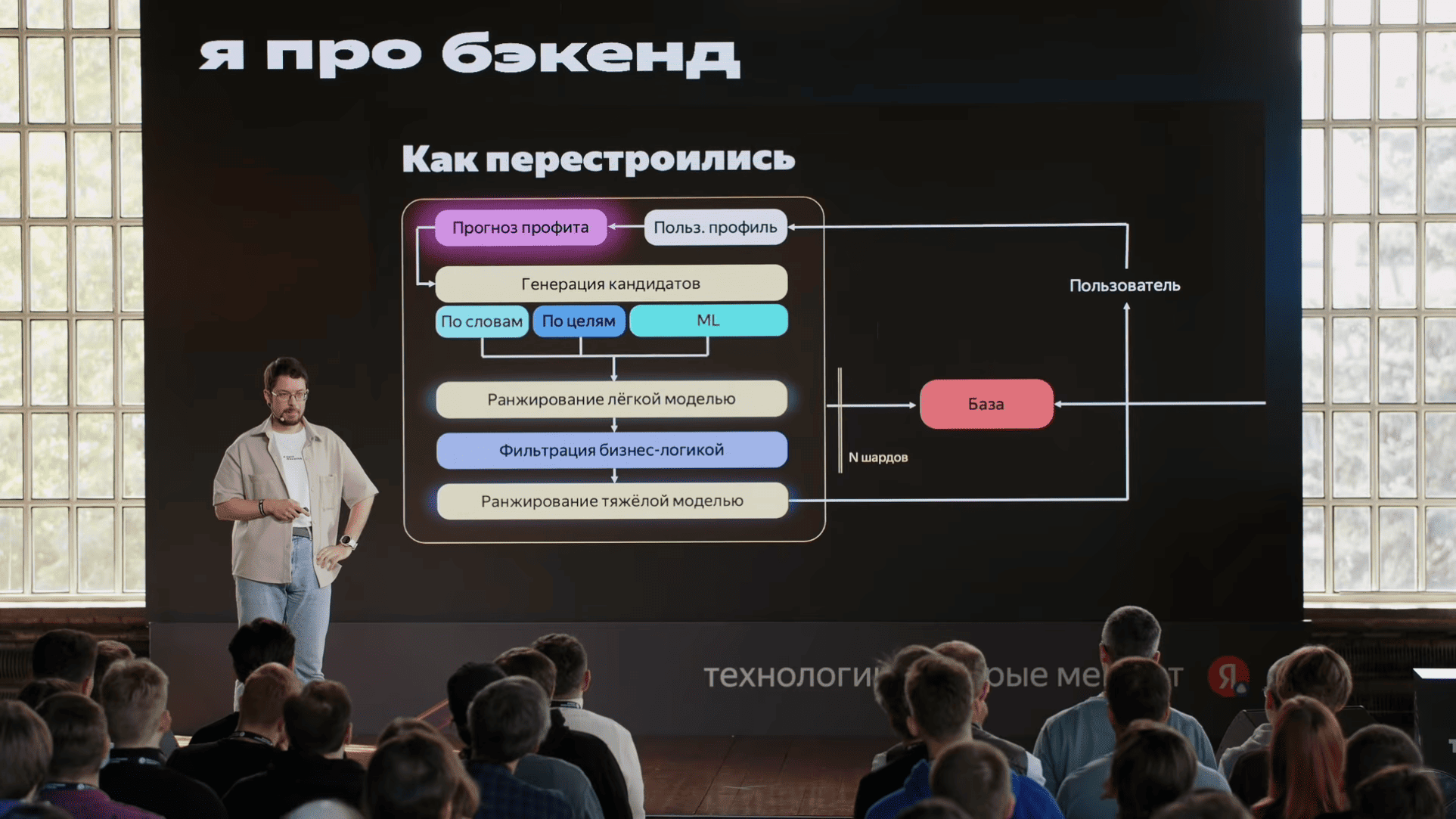
Например, когда ты хочешь рекламу на поиске показывать, ты можешь не просто сказать «сделать мне хорошо», а ты можешь выбрат, какое расширение поискового запроса для тебя актуально. Ты хочешь на запрос конкурентов показываться или нет? Хочешь ли ты на супер широких запрос показать или нет? И ты получаешь 5 галочек вместо утомительного заполнения кучи слов. И вот в такой комбинации оно работает хорошо. Оно и покупается людьми продуктово, и при этом эффективно с точки зрения рекламы.
Про фильтр, который по профиту отсеивает, показывать или не показывать. Как мне, как человеку, который формирует рекламную компанию, быть уверенным, что мои объявления не будут отфильтрованы вот по этому критерию, что они не приносят профита?
Мы выкидываем пользователей, которые не купят. И вот это как раз очень нужно рекламодателям, они нас за это уважают. Куски базы мы не выкидываем.
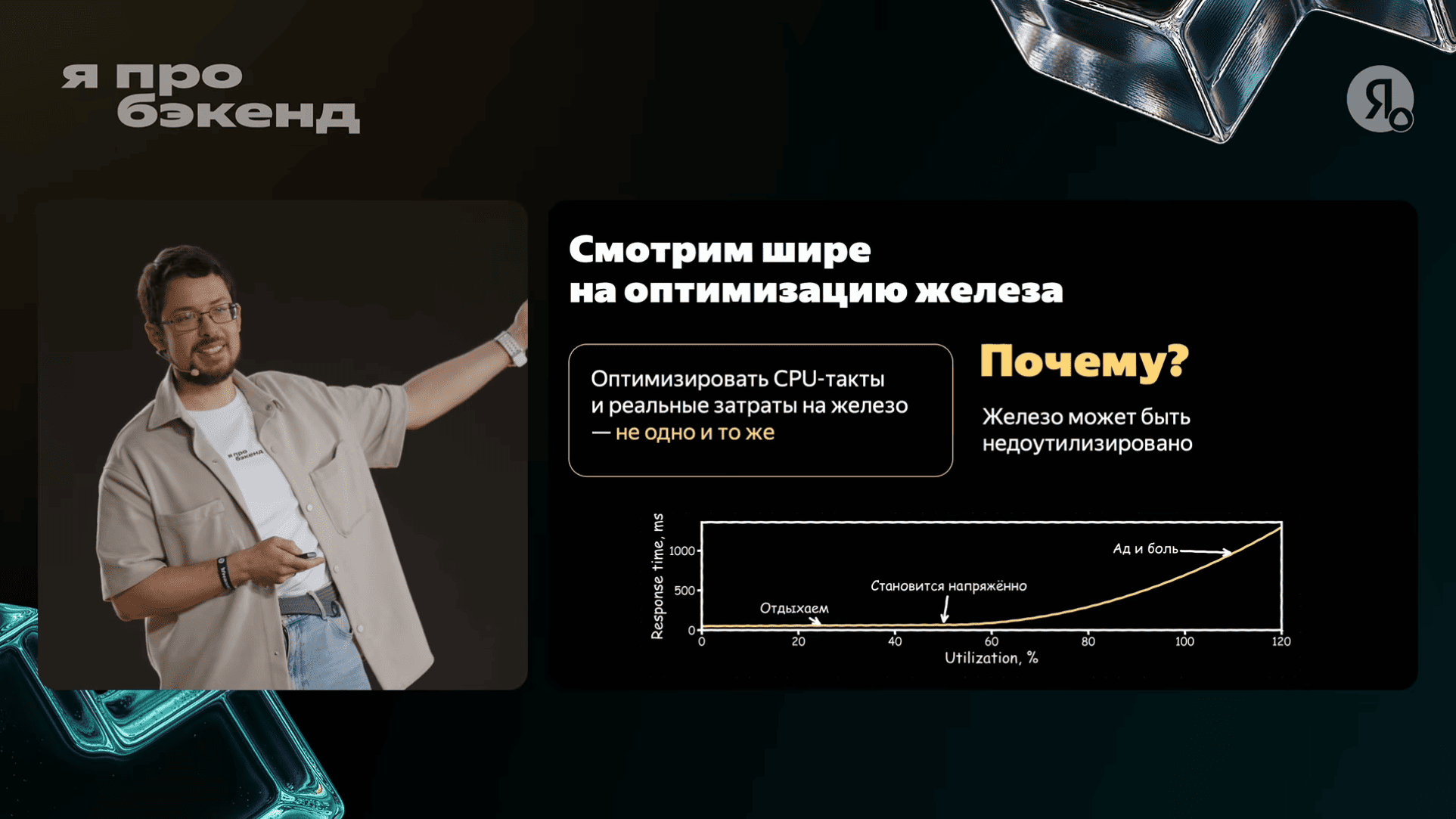
Как вы поступали с теми сервисами, которые хотят много CPU иногда, и поэтому должны держать на этом хосте или на этой железке какой-то излишний резерв?
Простой ответ — у нас таких практически нет. У нас есть сервисы, которые выгоднее залить железом на небольших объёмах, чем в них изобретать какую-то деградацию, потому что там просто будет больно вот это всё. Такое есть, но мы их просто не трогаем.
То есть я правильно понимаю, что для этого нужно, чтобы сервисы позволяли такую модель масштабирования?
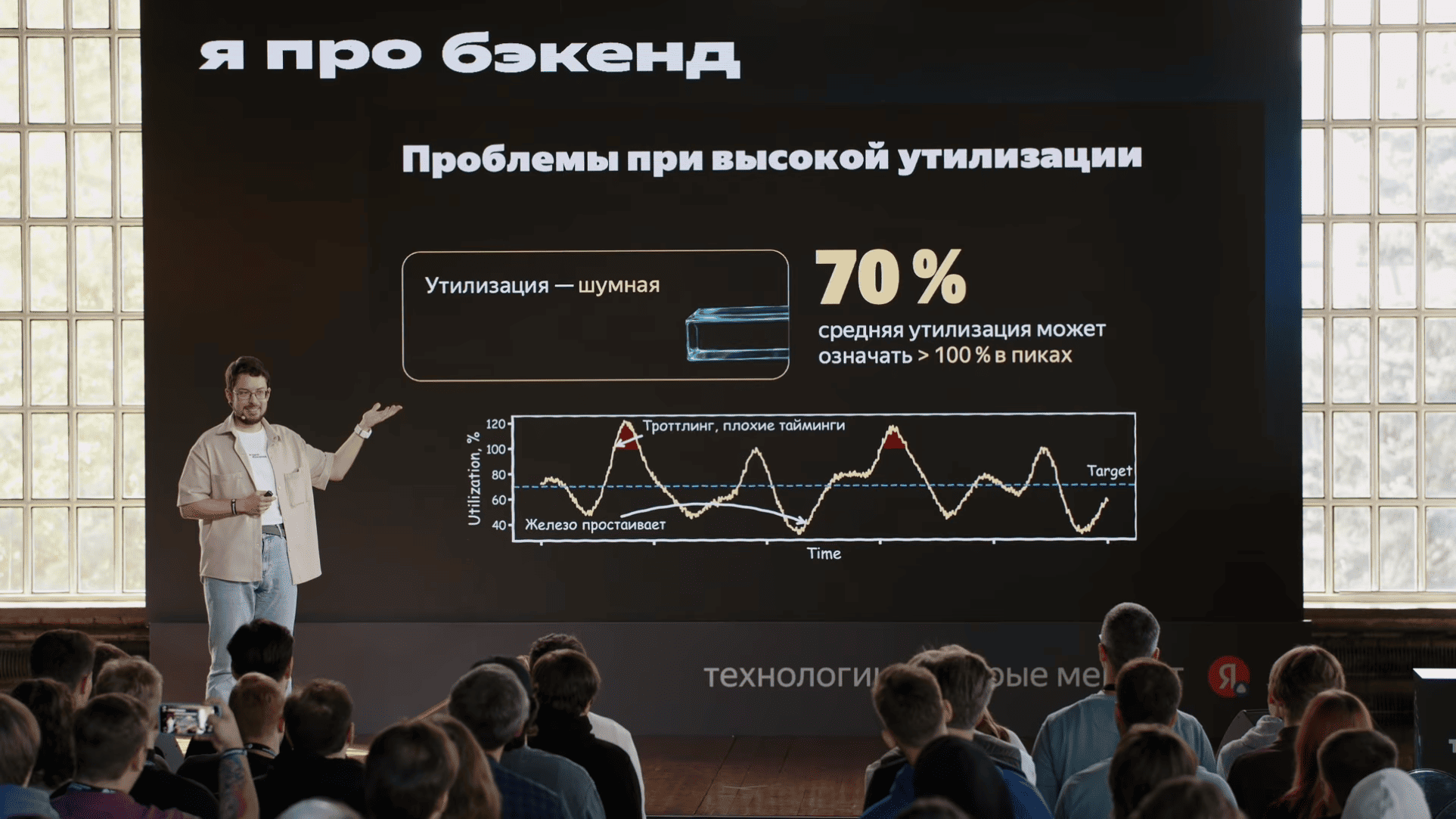
Вы имеете в виду, что можно отсекать запросы, да? В целом, да, но вообще-то вот подобные трюки с шедулером, про них, например, Uber писал свои статьи, и мы у них подглядели про PID-контроллер. Поэтому на самом деле оценивать важность конкретного запроса в принципе важно везде. Так или иначе, каждый отдельный запрос приносит разную ценность бизнеса.
Я так понял, вы около 5 лет всей этой истории занимались, да?
Лично я?
Вообще команда.
Команда занималась какими-то историями буквально год, а история с перекладыванием данных в разных форматах ну лет 10, мне кажется.
То есть у вас за это время сервера не менялись. Вы говорите так смело, мы сэкономили столько-то процентов, столько-то процентов. А сервера живут 3-4 года, потом...
Сервера постоянно меняются. Я скажу хуже, мы стали жрать больше железа за это время. Потому что параллельно растет трафик, бизнес растет, но мы обгоняем эту скорость. Мы растем не на 30% железа каждый год.
А теперь, главный вопрос, а как вы убедили бизнес, что вот эта разработка вам когда-то через год принесет денег?
Очень легко. Мы в 20-м году просто лежали кучу времени.
Это само так получилось, получается, да?
Нет, но теперь-то я могу приходить к CTO, значит, и говорить, что смотри, Леша, мы там, значит, сэкономим железа настолько, это можно разменять дальше на деньги, и все очень понятная математика. Это сейчас, как бы легко говорить, да, тогда было сложнее.
Я посмотрел вашу выручку за 2024 год, именно Поиска, а не всего Яндекса. Это 439 миллиардов, плюс 30% год году. Экономия твоих 200 тысяч CPU на год по ценам Яндекс Облака, а у вас стопудово дешевле, где-то 2 миллиарда. Экономия вот этой инженерной бизнес-задачи 0.5% при том, что вы растете 30% год к году. Побочка все-таки экономия 200 CPU решения какой-то инженерной задачи, или это была именно цель? Почему я спрашиваю? Потому что я хочу продать своему бизнесу экономию миллиарда в год. Мне говорят, у нас тут CAPEX на сто миллиардов, чтобы дата-центр построить. Вообще нафиг не надо. Давай твои инженеры будут заниматься другой задачей.
Тут два фактора. Очень классный вопрос на самом деле. Первый фактор с тем, что бизнесу в какой-то момент нужно было налить сильно больше трафика. И они бы не налили этот объем трафика, если бы не смогли так соптимизироваться. Это первая часть.
Это из-за 2022-го года и из-за времени поставок железа?
С одной стороны 2022-й год, с другой стороны это расширение бизнеса в некотором смысле. Всевозможный разный внешний трафик других рекламных систем, которые нужно уметь переваривать, которых по миру просто очень-очень много, мы его все еще не весь обрабатываем. Второе, это все-таки тот факт, что мы можем эффективно разменивать железо на деньги, там очень классная маржинальность на самом деле.
Я могу сказать, что все-таки это была побочка, но которую ты уже превратил в бизнес-историю.
Получается, что да.