06 октября 2025 г.
Здравствуйте. Меня зовут Сергей Трегуб. Я руковожу бэкенд-разработкой продуктовых сервисов Яндекс 3060.
Каждый разработчик, когда слышит слово «архитектура», в первую очередь представляет себе картину из блоков, соединенных стрелочками, которая показывает структуру системы и связи между ее частями. Крупноблочная архитектура — это модель системы, по которой мы понимаем, из каких ключевых компонентов она состоит. Как компоненты связаны между собой? Как взаимодействуют? Какие данные хранить система? И как ими обменивается? Однако все это без погружения в детали бизнес-логики.
Компоненты обычно представляют собой верхнеуровневые строительные блоки, такие как хранилища данных, очереди сообщений и кластера воркеров, балансировщики нагрузки, микросервисы и многое другое. Такую моделью удобно пользоваться для эффективной коммуникации с различными командами разработки, вовлеченными в проект. При обсуждении развития продукта мы используем эту модель, чтобы решить, в каком компоненте стоит разместить новую бизнес-логику или какие новые компоненты для этой логики нам необходимо добавить. При планировании, масштабировании системы на такой модели мы с легкостью можем найти узкие места и продумать стратегию их расширения. Для описания такой модели нам достаточно прямоугольников и стрелочек. Главное, чтобы она была понятна нашей команде. Чем проще, тем лучше. Но можно использовать и формальные нотации, такие как UML или C4. Это позволит легче находить общий язык с командами, слабосвязанными между собой и взаимодействующими от случая к случаю на разных проектах.
Путь к такой картине лежит, как правило, через определение требований, функциональных и нефункциональных, и внешних API, о которых мы говорили в предыдущих сериях. Давайте представим, что требования определены, внешние интерфейсы системы прописаны. И мы с вами погружаемся в крупноблочную архитектуру одного из старейших сервисов Яндекс 360 — Календаря.
Яндекс Календарь представляет собой типичное веб-приложение. Набор компонентов, из которых он состоит, мы можем встретить практически в любом облачном сервисе. Первое, с чем мы сталкиваемся, когда начинаем работать с календарем, это веб-приложение. Оно работает в браузере и представляет собой HTML-разметку, JavaScript- и CSS-код. Статика подгружается из распределенного CDN. JavaScript-код взаимодействит с пользователем, ходит в бэкенд за данными и отображает их в интерфейсе.
Запросы из веб-приложения попадают в BFF. Это аббревиатура для backend for frontend. В нашем случае это легковесный веб-сервер, у него несколько задач. С одной стороны он представляет удобный для веб-приложения API, который не скован требованиями к публичному API. Он обогащает данные, которые возвращаются бэкендом перед их отправкой на фронтенд. С другой стороны, BFF обеспечивает возможность серверного рендеринга, который позволяет существенно снизить время до первой отрисовки пользовательского интерфейса. Наша команда состоит из бэкенд- и фронтенд-разработчиков. Фокус первых — обеспечивать надежность и масштабируемость. Фокус вторых — создавать лучший на рынке пользовательский опыт. Выделение BFF как отдельного сервиса позволяет нам развязать команды с разным фокусом и разделить релизные циклы и процессы разработки.
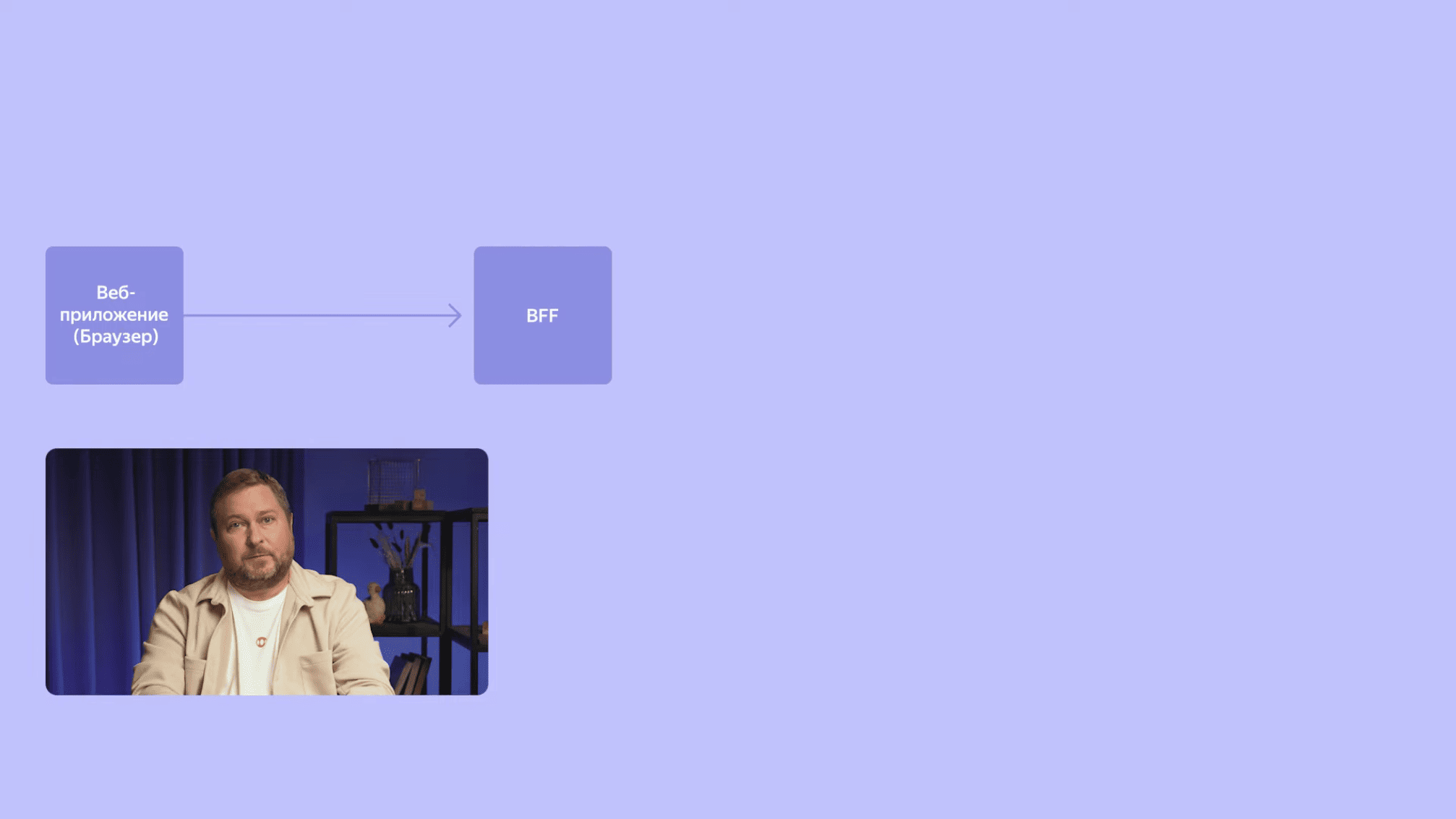
В Календаре у каждого пользователя свой набор встреч, а значит необходимо, чтобы пользователь проходил аутентификацию и авторизацию в нашем приложении. Для этого веб-приложение отправляет пользователя на внешний Identity Provider. Там пользователь проходит аутентификацию и возвращается в приложение Календаря с заголовками, по которым мы определяем, какие данные доступны пользователю. На BFF мы обмениваем эти заголовки на внутренний подписанный идентификатор запроса, содержащий в том числе ID пользователя. Все запросы в BFF-бэкенды и между бэкендами содержат этот уникальный идентификатор.
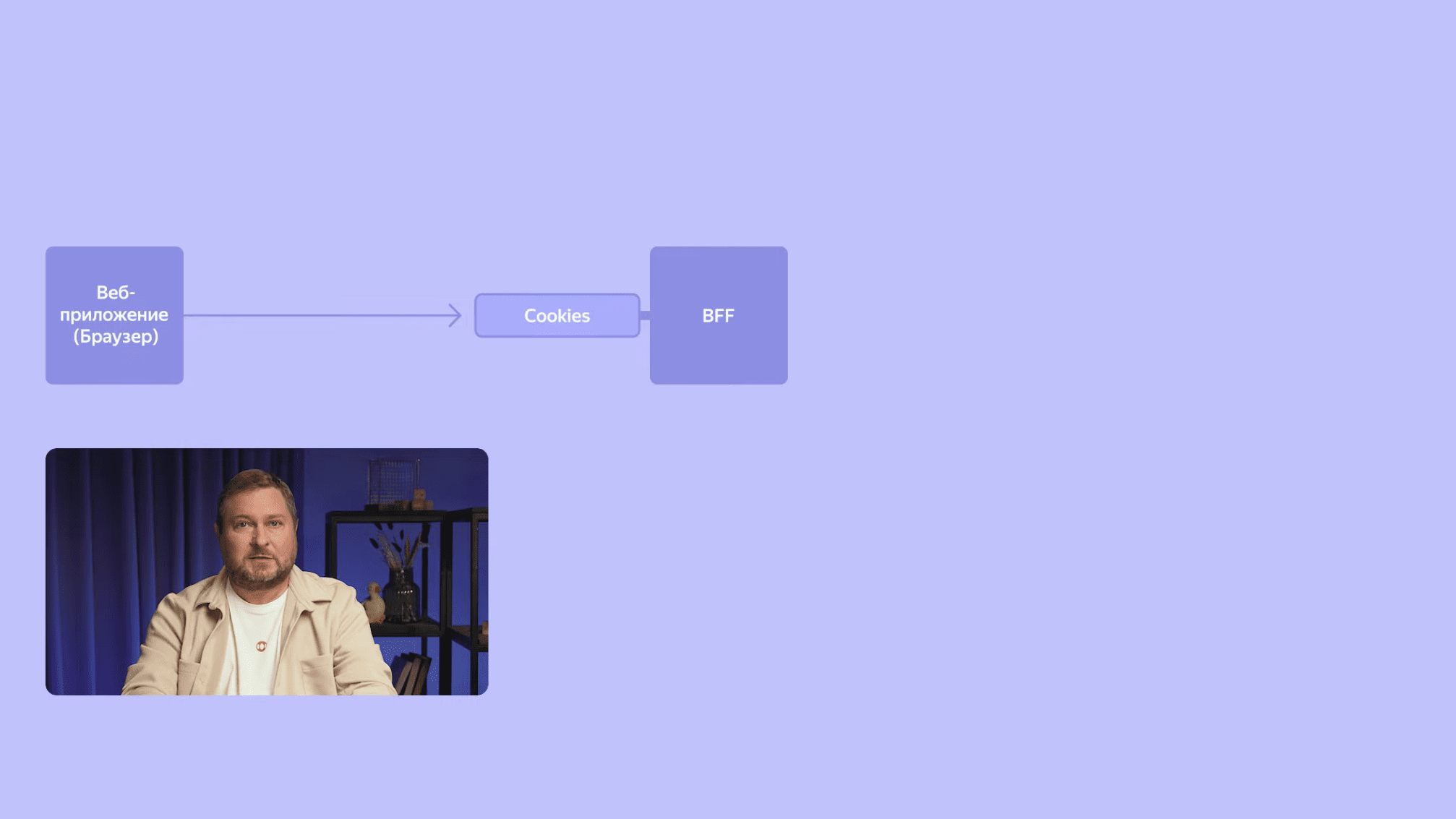
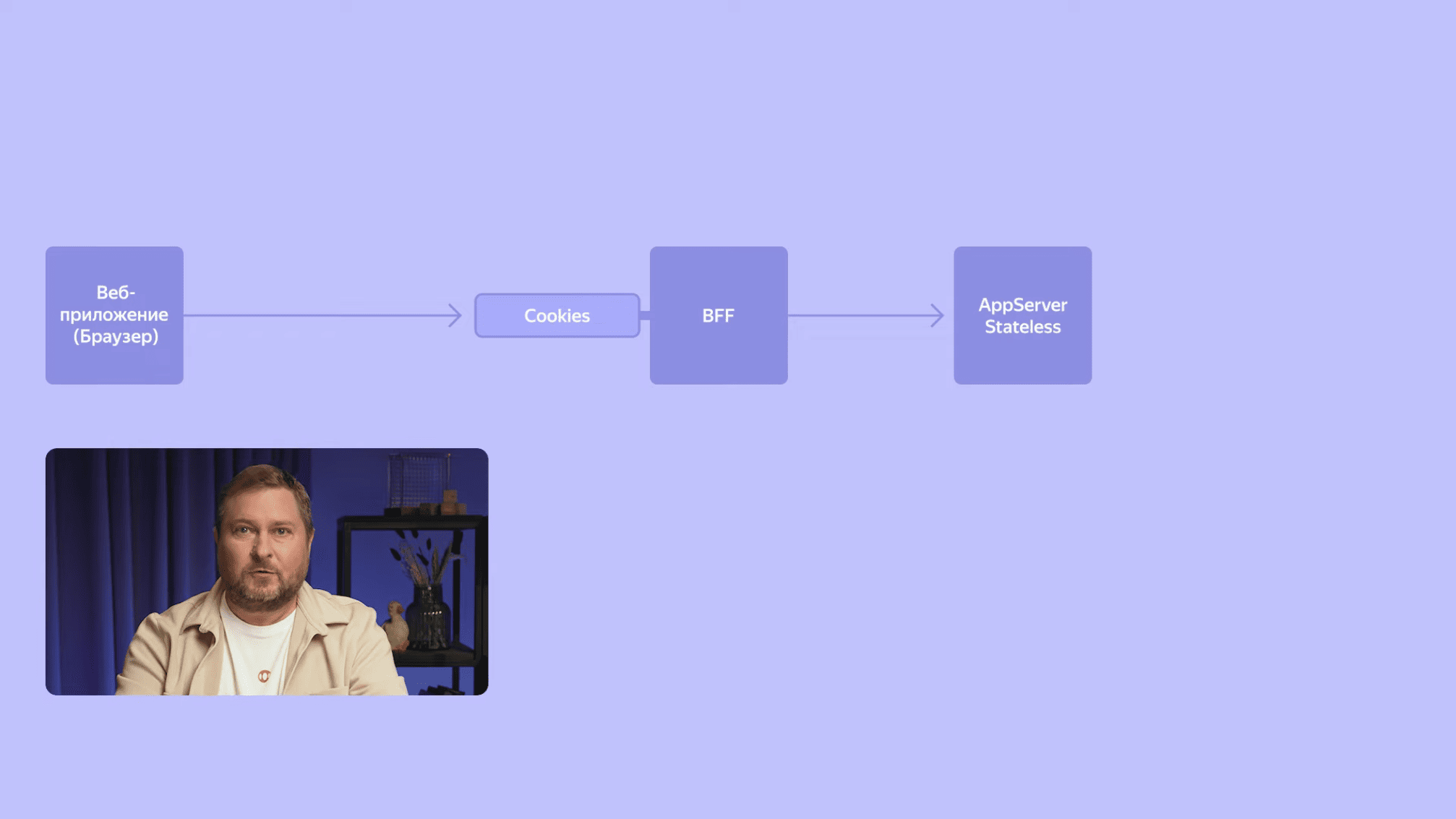
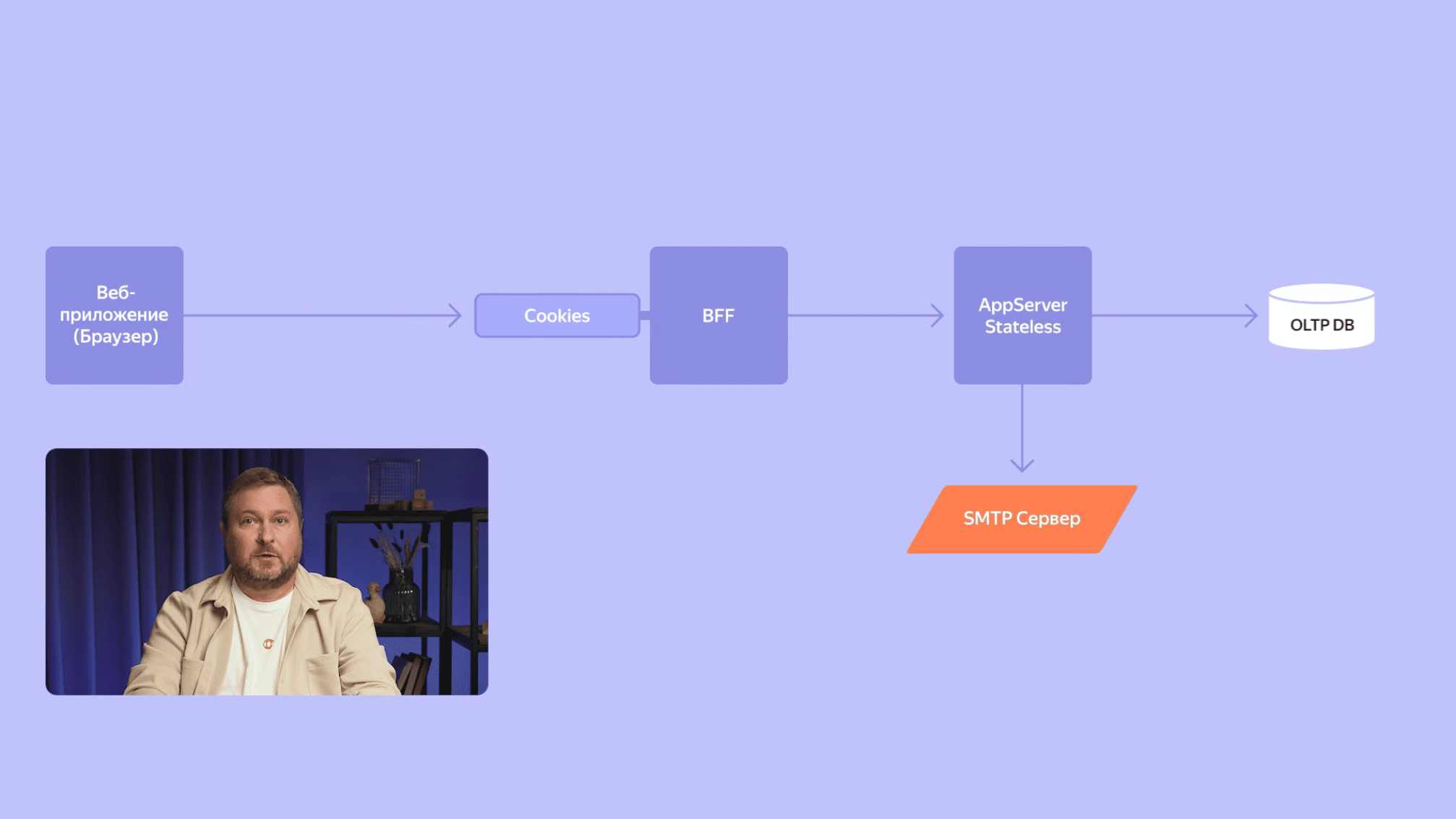
Мы продолжаем погружаться в глубины Календаря, и наш запрос наконец достигает бэкенда, в котором реализовано бизнес-логика. Бэкенд Календаря – это сервис, предоставляющий RESTful API. BFF взаимодействует с ним синхронно, запрос-ответ. BFF отправляет запрос и ждет получения ответа от сервера. Не нужно путать синхронные взаимодействия между сервисами и синхронные или асинхронные операции ввода-вывода. BFF в синхронном стиле взаимодействует с бэкендом, но используют при этом асинхронные операции ввода-вывода, чтобы экономнее расходовать ресурсы и обрабатывать больше параллельных запросов.
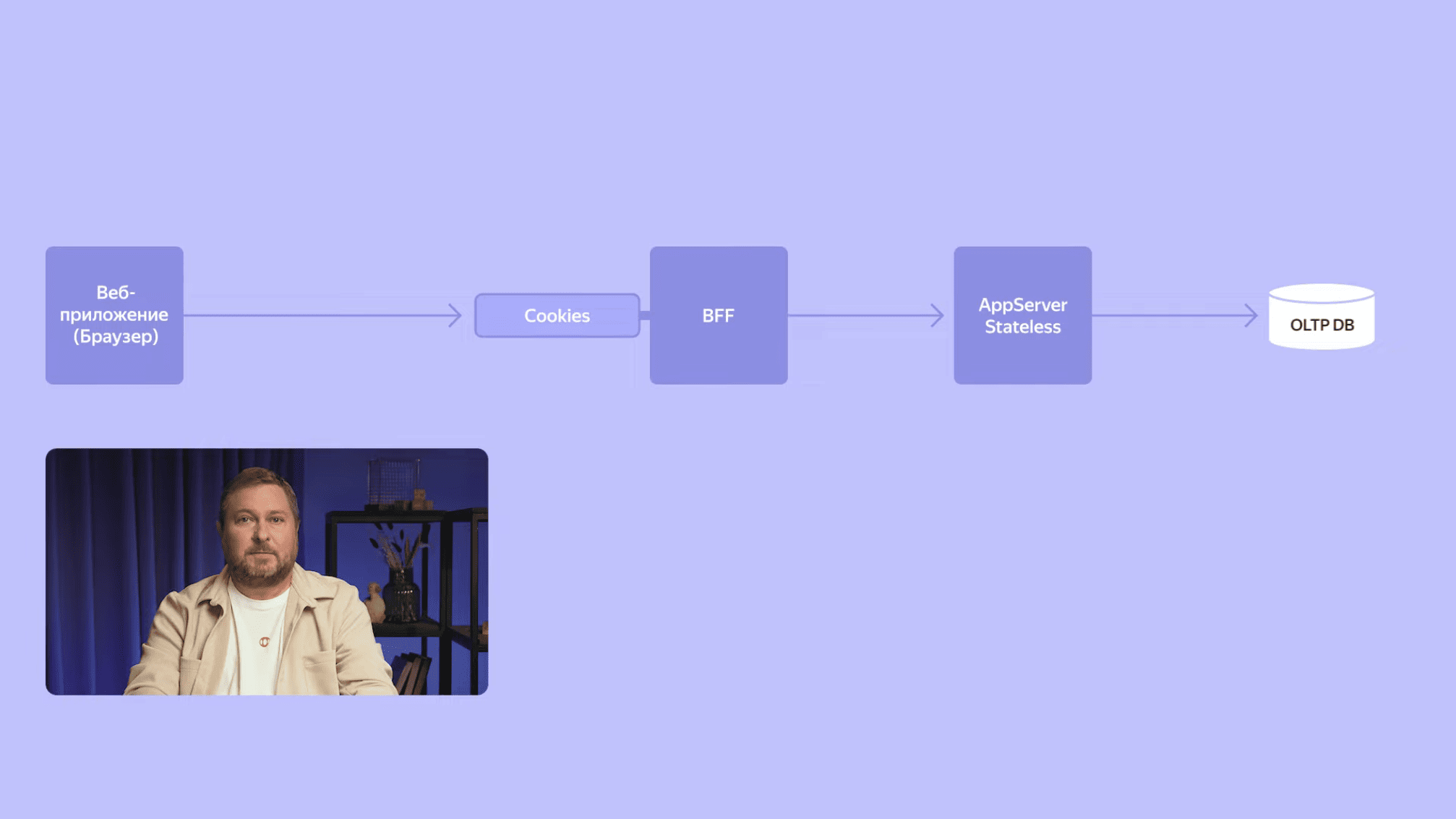
Наш бэкенд реализован как stateless-сервис. Это означает, что он всё необходимое для обработки запроса получает либо из параметров самого запроса, либо из внешнего источника — другого сервиса или база данных. Между запросами никакого состояния в памяти сервиса не сохраняется. Благодаря этому свойству мы имеем возможность поднимать параллельно большое количество экземпляров нашего сервиса, чтобы обрабатывать запросы миллионов пользователей.
Продолжая погружаться дальше, мы наконец достигаем самых глубин бэкенда — хранилища данных. Если мы присмотримся внимательнее, то обнаружим здесь в самых глубинах, куда не проникают взоры обычных пользователей, старый добрый PostgreSQL. Особенностью календаря является то, что нам необходимо использовать много коротких транзакций, в каждой из которых читается или пишется относительно небольшой объем данных, с чем PostgreSQL отлично справляется. Кроме того, PostgreSQL очень надежен и предсказуем. Если у него достаточно процессора, памяти и индексов, то он очень производителен. Если возникают проблемы, то практически всегда это либо нехватка ресурсов, либо плохо написанный запрос.
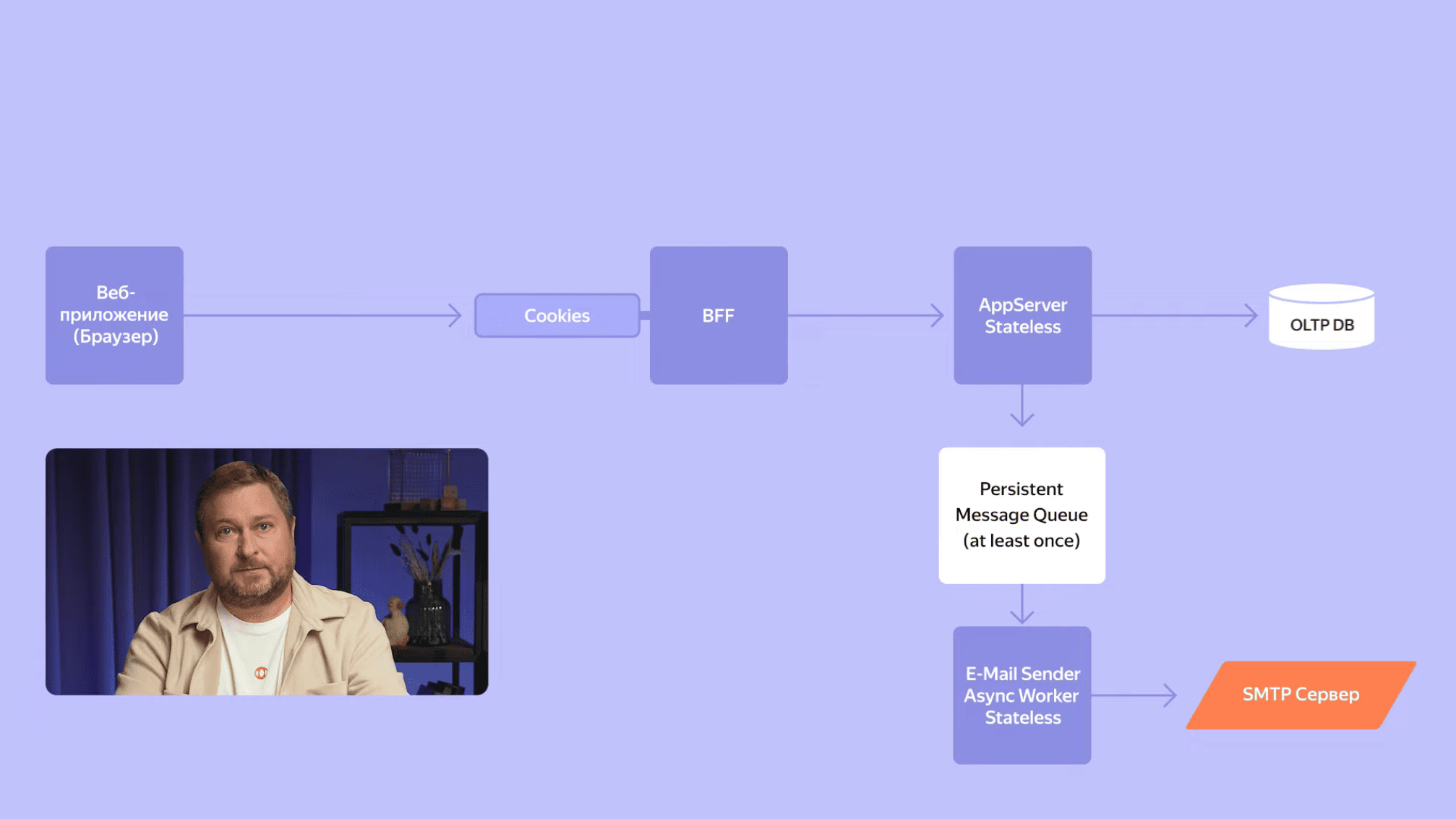
Давайте вернемся немного назад. Помимо сохранения и редактирования встреч одной из ключевых функций календаря является отправка уведомлений о скором начале встречи или о ее изменении. Для того, чтобы отправить письмо, нам необходим почтовый сервер. Мы используем сервер Яндекс Почты, который является частью нашей экосистемы. Каждый раз, когда что-то меняется во встрече, мы отправляем письмо каждому участнику. Во встрече могут быть сотни и даже тысячи участников. Предположим, отправка одного письма занимает порядка 100 мс. Тогда отправка тысячи писем займет уже 100 секунд, больше полутора минут. При этом мы же помним, что при создании встречи интерфейс-календаря и сервиса взаимодействуют синхронно, а значит пользователь, который создает эту встречу, будет полторы минуты грустно смотреть на надпись «Подождите, встреча создается». Чтобы этого не происходило, мы используем асинхронную рассылку писем. Для этого задействуем очередь сообщений и пул воркеров, которые разгребают эту очередь.
В процессе создания встречи каждое письмо вместе с адресом получателя мы сериализуем в JSON и складываем его в очередь сообщений. Нам необходимо, чтобы письма гарантированно доставлялись, поэтому используем персистентную очередь с гарантией доставки at least once. В нашем случае это YDB Topics, аналог Kafka, но для крупноблочной архитектуры это не важно. Это просто персистентная очередь с необходимыми гарантиями доставки. А чтобы избежать дубликатов писем, мы к каждому письму добавляем ключ идемпотентности.
Наши воркеры не имеют HTTP API, вместо этого они слушают топики очереди, вычитывают оттуда сообщения, десериализуют их и отправляют на почтовый сервер. Воркеры реализованы как stateless-сервисы, как и основной бэкенд. Это позволяет нам без дополнительных усилий поднять столько воркеров, сколько нам необходимо, чтобы успевать обрабатывать все сообщения в очереди и гарантировать быструю отправку письма. Благодаря такому подходу мы можем рассылать сотни тысяч писем в минуту, а пользователи Календаря не замечают никаких задержек, и каждое письмо находит своего адресата в считанные секунды.
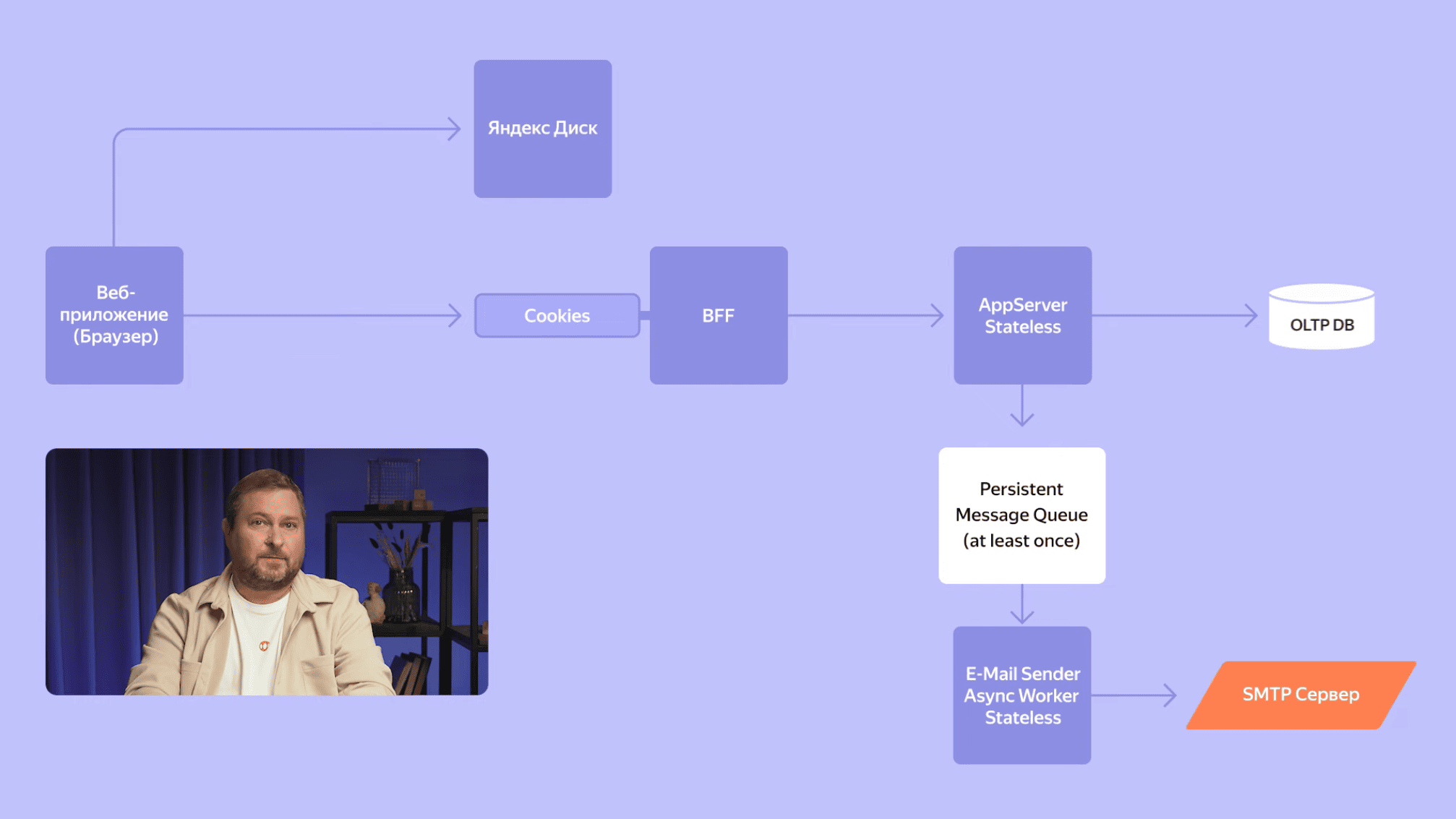
Продолжаем подниматься наверх из стека вызова Календаря и снова возвращаемся к интерфейсу пользователя, чтобы рассмотреть поближе, как Календарь сохраняет файлы, которые мы можем прикреплять к встречам. Интерфейс напрямую взаимодействует с Яндекс Диском. Календарь загружает файл на Яндеск Диск и прикрепляет ссылку к встрече. Это хороший пример решения сложной задачи, используя уже существующие строительные блоки.
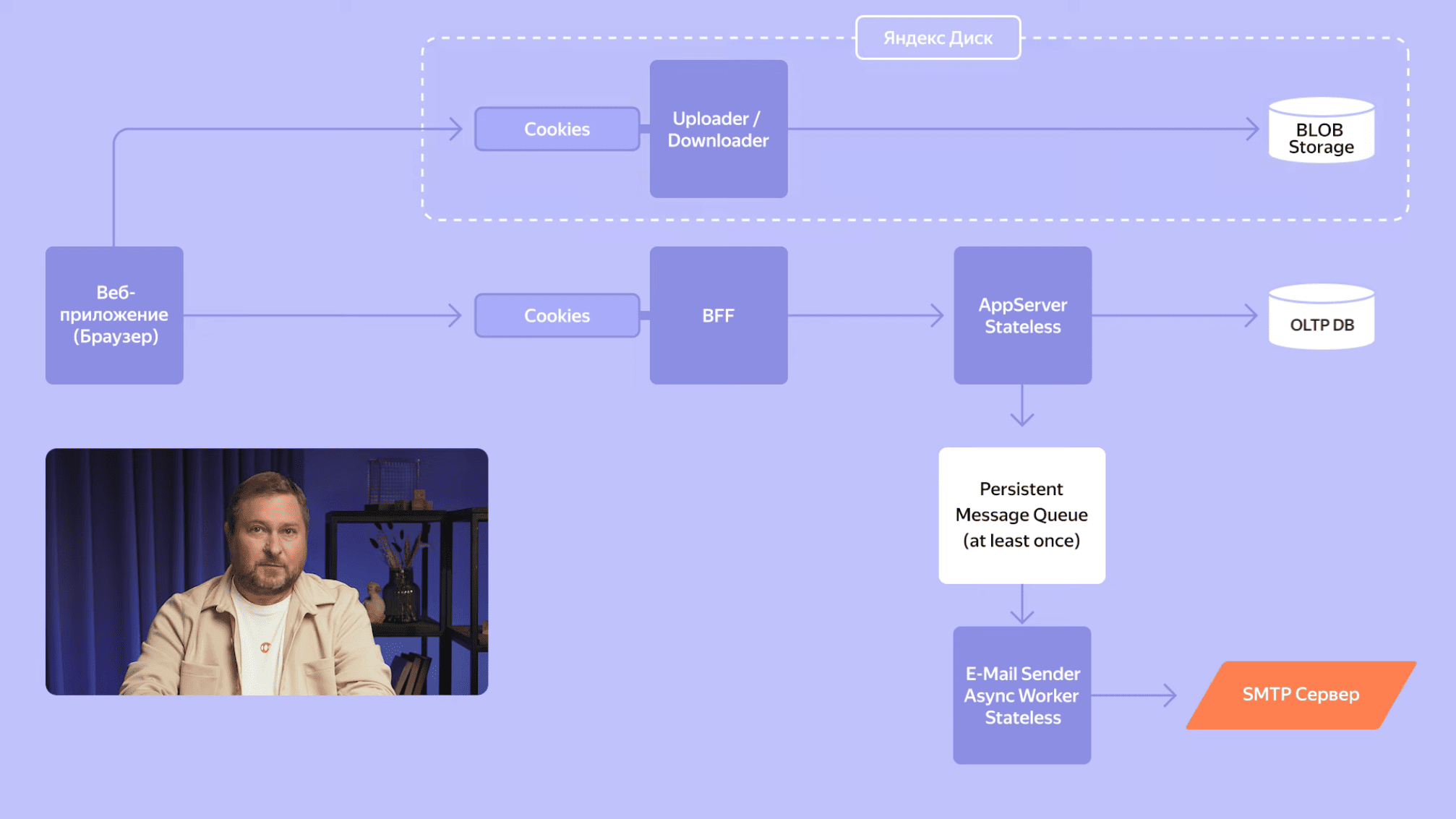
Но давайте заглянем еще глубже и разберемся, что происходит с файлами в Диске. Здесь нас встречает старый знакомый, stateless-сервис с аутентификацией и авторизацией, что очень похоже на комбинацию BFF и бэкенда Календаря. Он выполняет роль привратника, который пускает дальше только те запросы на загрузку файлов, которые прошли проверку, и контролируют, чтобы никто не мог получить доступ к чужим файлам. За ним скрывается Blob Storage. Это KV-хранилище, способное горизонтально масштабироваться по объему данных практически бесконечно. Его задача — хранить экзобайты бинарных данных и отдавать их с максимальной скоростью, если они вновь понадобились пользователю.
Крупноблочная архитектура сервиса — это план или крупного штабная карта, которая помогает нам понять, где лучше разместить те или иные функции в системе, как их связать между собой и с внешними системами. Позволяет смоделировать работу системы и убедиться, что мы не упустили никаких крупных строительных блоков, необходимых для реализации задуманного. Она, как макет здания, позволяет наглядно визуализировать концепцию системы, проверить инженерные и композиционные решения, оценить взаимосвязи системы с окружающей средой и архитектурным ландшафтом. Помогает презентовать идеи разработчикам, смежным командам и заказчикам.
В следующих частях мы посмотрим на более практические аспекты, какие проблемы возникают в реальной жизни и как их можно решать.