25 мая 2024 г.
Всем привет! Как Олег представил, меня зовут Алексей Быков, я бэкенд разработчик Яндекс Go. И помимо разработки бэкенда занимаюсь также координацией инцидентов. Команда, в которой я работаю, это одна из команд в Такси, которая улучшает доступность Такси как сервиса, и одна из ключевых целей в рамках повышения доступности Такси — это предотвращение долгих падений, долгих отказов.
Почему? Потому что с точки зрения тех людей, которые пользуются нашим сервисом — это и пользователи, и водители, — долгие отказы достаточно болезненно воспринимаются. То есть, если такси не работает долго, люди не могут совершить какую-то запланированную поездку на деловую встречу, в аэропорт, к врачу. Если сервис долго не работает, водители лишаются возможности зарабатывать деньги. Поэтому длительные отказы — это достаточно неприятная история. Кратковременные отказы тоже достаточно неприятны, но если там Такси не работает 2-3 минуты, то в большинстве случаев люди могут подождать и сделать заказ попозже.
Одна из, наверное, таких самых распространённых причин, почему сервисы — большие сервисы и не только большие, — складываются надолго — это такой класс отказов, который ряд источников называют как Metastable Failure, или про систему говорят, что она входит в состояние Metastable Failure State. Этот термин придуман не нами, он разными компаниями в разных статьях упоминается. Есть даже статьи, в которых он вводится и объясняется его происхождение. Ниже приведён набор ссылок с разбором инцидентов в крупных сервисах, которые как раз по данному классу отказов падали. Видно, что там как бы отказы были длительные. В общем, это всё было довольно неприятно. Проблема невыдуманная, встречается не только у нас.
Разбор инцидентов в крупных сервисах:
Как будет устроен доклад? Доклад разбит на три части:
1Сначала попробуем на примере простой системы разобраться, как вообще так происходит. Почему система может так сильно упасть, что она долго не поднимается, и сама она не может выбраться из такого плохого метастабильного состояния.
2Во второй части попробуем на примере из первой части и на паре других примеров как-то обобщить полученные знания, сформулировать какие-то тезисы.
3В третьей части расскажу, как мы в Такси пытаемся предотвратить такие падения, а если уж не получилось предотвратить, что мы с этим делаем, чтобы их побыстрее починить.
Поехали! Предположим, что у нас есть какой-то сервис такси, довольно несложный, молодой. Как он устроен? Есть мобильное приложение, пользователи вводят параметры поездки. Мобильное приложение отправляет запрос на бэкенд, рассчитывается стоимость. Если пользователь согласен на стоимость, он нажимает кнопку "Заказать", и всё — заказ создан, дальше происходит поиск исполнителя.
Сервис молодой, ещё никаких микросервисов нет. Мобильные клиенты приходят в какой-то монолитный бэкенд для обработки запросов пользователей, возможно уходит в базу данных, чтобы сохранить какие-то персистентные данные. Ничего необычного — типичная довольно несложная архитектура.
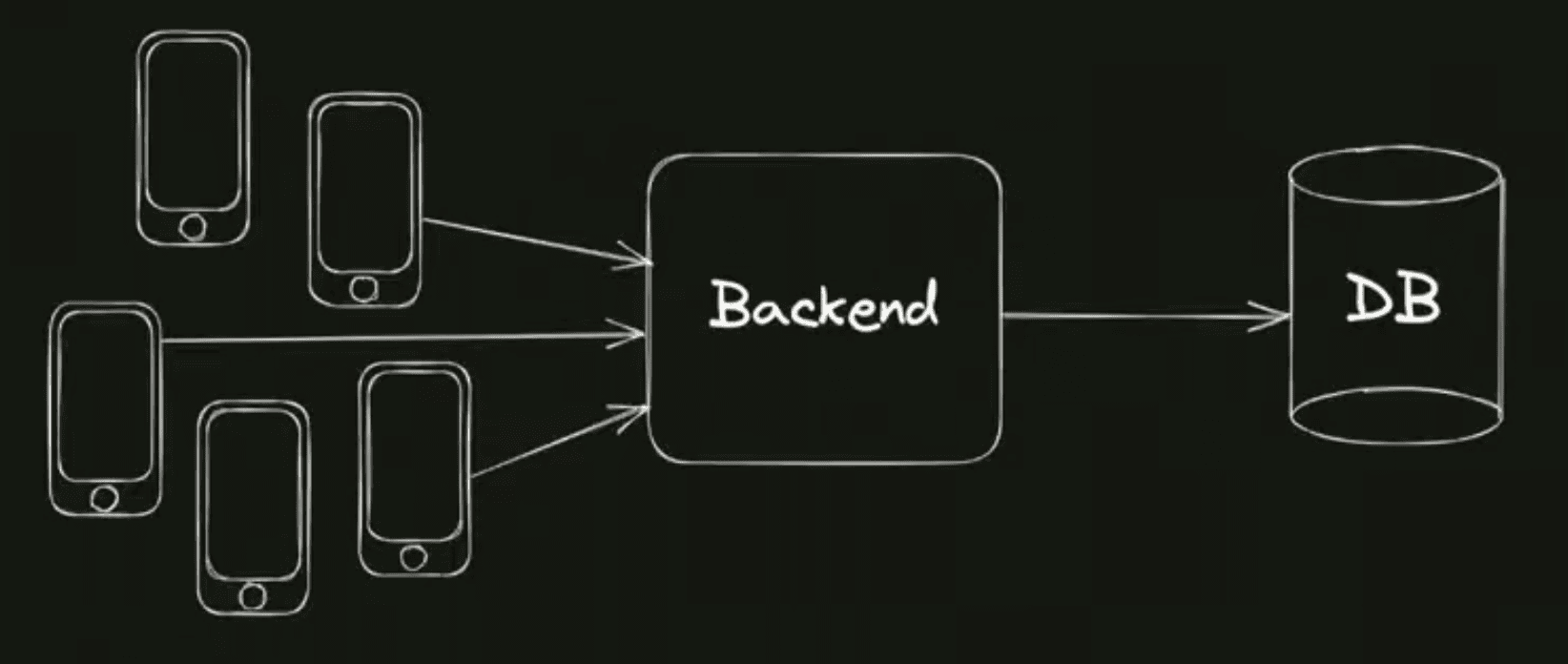
Систему запустили, тестируют и видят, что иногда случается такая ситуация, что цены не отображаются в приложении. Начали смотреть, почему так происходит, заметили, что иногда бэкенд отвечает дольше какого-то таймаута, которые мобильное приложение выставляет на запрос, и цены не прогружаются. Случается это довольно редко. Но при этом пользователи всё равно недовольны.
Собрались, обсудили, что делать, и решили добавить в клиентские запросы ретраи — если с первой попытки не получилось ответ на запрос получить, то делается ещё одна или две дополнительные попытки, пока успешный ответ не получен. Большинство ошибок таким способом лечится, всё хорошо.
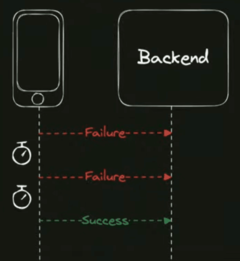
Как работать с ретраями:
Запустились, сервис работает, есть пользователи. Команда собрала дашборд, есть мониторинг системы. Что на дашборде можно увидеть?
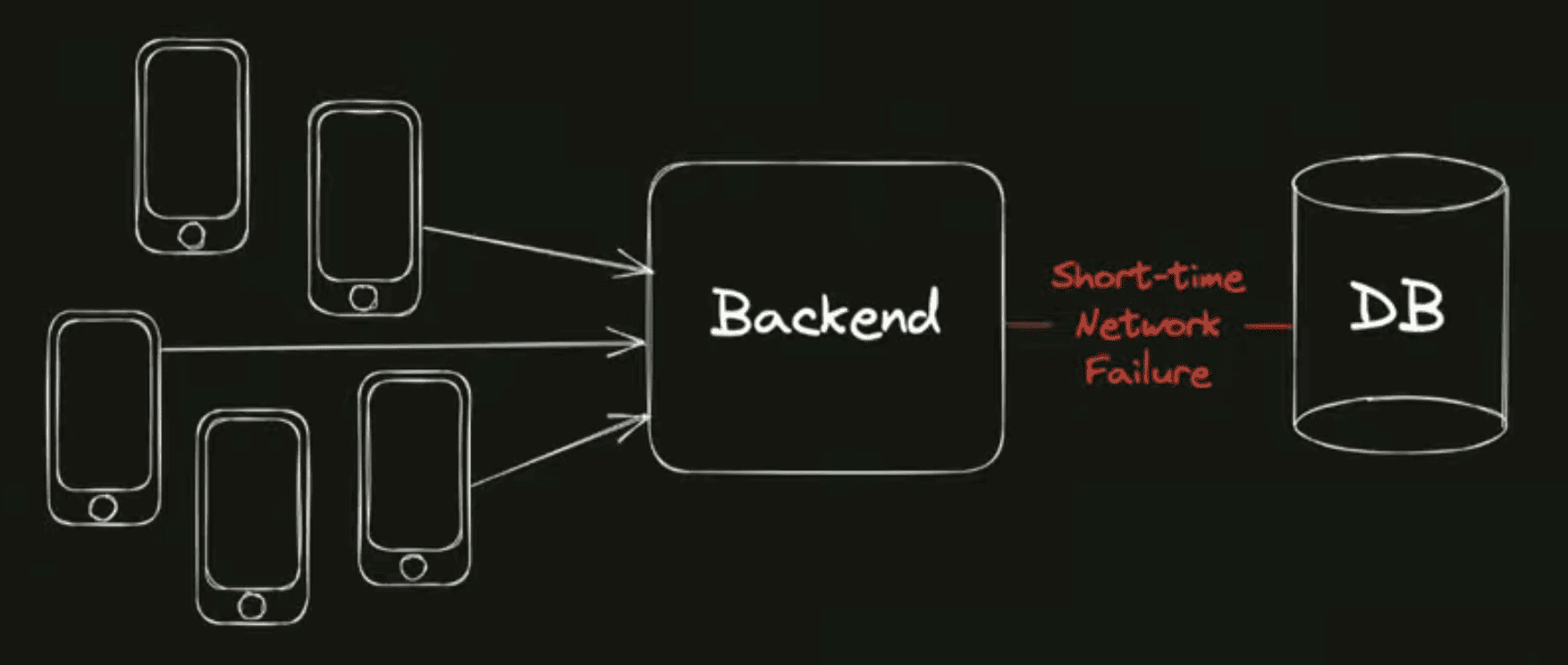
Теперь представим, что в какой-то непредвиденный момент времени случается такая неприятность. То есть происходит какое-то непредвиденное событие, здесь и дальше мы будем называть его термином "Триггер".
Что произошло? Между бэкендом и базой данных на какой-то короткий промежуток времени потерялась сетевая связанность. То есть бэкенд не мог достучаться до базы данных и запросы выполнять. Но поломка была кратковременной, и спустя 5 секунд сетевая связанность была восстановлена, и бэкенд снова может работать с базой данных. При этом с сервисом случилось что-то неприятное, команда смотрит на дашборд, и что она видит?
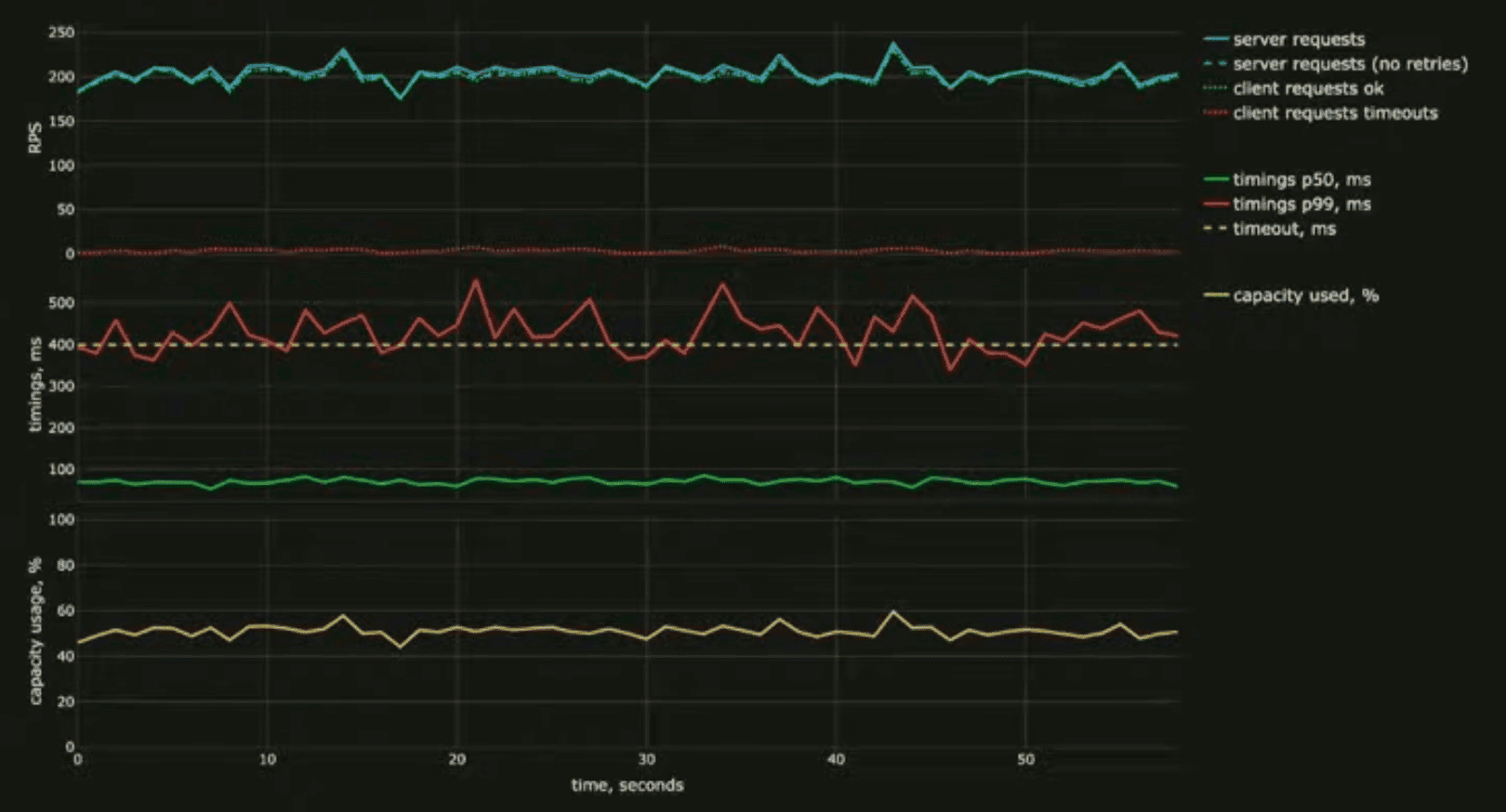
Красным подсвечен тот промежуток времени, когда сетевой связности не было, но посоле того как она восстановилась, метрики системы не вернулись в норму.
На первом графике мы видим, что очень сильно выросла входная нагрузка, примерно в три раза. Если раньше мы получали где-то 200 запросов в секунду, то сейчас нагрузка 600 запросов в секунду. При это клиенты практически перестали получать успешные ответы — зелёная пунктирная линия практически возле нуля. То есть клиенты никакие цены не получают, что мешает им заказ сделать, и практически все запросы таймаутятся.
Собственно, это можно объяснить, посмотрев на второй график. У нас выросли тайминги ответа бэкенда, они практически все выше клиентского таймаута. То есть клиент не может получить ответ, и в приложении ничего не отображается.
Также мы видим, что бэкенд упёрся в лимиты своих ресурсов — утилизация 100%. Очевидно, что система перегружена и ей ресурсов не хватает.
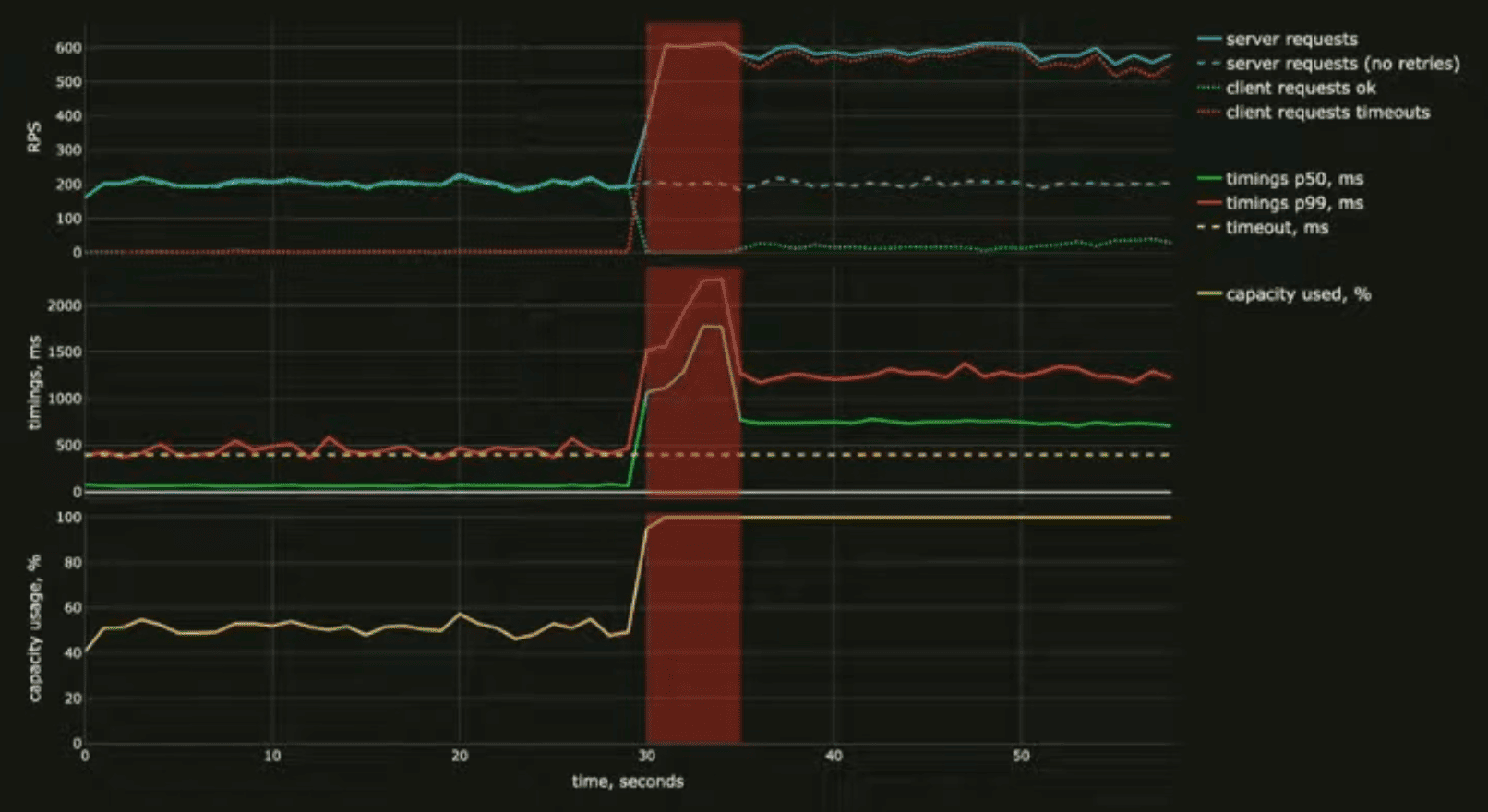
Как правило, когда вы смотрите на какой-то взрыв системы на графиках, довольно тяжело понять причинно-следственную связь. Даже в высоком разрешении графиков, если у вас там минуты или десятки секунд, всё происходит в какой-то один момент, это одна точка во времени, и по графикам понять, что повлекло за собой какие последствия, не очень понятно.
Давайте попробуем разобраться:
1Сначала система у нас была в стабильном состоянии, всё было хорошо, сервис работал
2Потом случился триггер — это потеря сетевой связности
3Из-за этого, так как бэкенд не мог ходить в базу данных, выросли тайминги бэкенда, причём выросли достаточно сильно, и клиенты стали получать тайм-ауты на свои запросы
4Так как клиенты таймаутились, они делали ретрай запросов — та фича, которую мы сделали, чтобы починить тот небольшой фон ошибок
5Из-за ретраев на систему пришла достаточно большая избыточная нагрузка. Тот троекратный рост нагрузки, который мы видели на графике, объясняется тем, что практически на каждый неуспешный ответ клиент делает две дополнительные попытки запроса, и суммарно у нас нагрузка на систему выросла в три раза
6Так как ресурсы в системе закончились — мы видели это по графику утилизации ресурсов системы, — то система перешла в перегруженное состояние
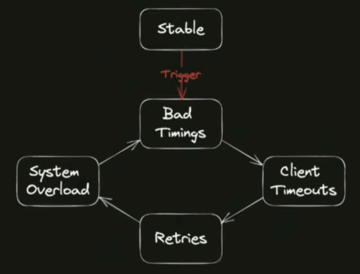
Здесь вот ключевой момент пазла — когда система находится в состоянии перегруза, это само по себе влечёт за собой ухудшение таймингов системы, потому что процессорного времени не хватает для обработки запросов, и запросы из-за этого обрабатываются дольше.
Даже если после того, как система вошла в это состояние, триггер может исчезнуть — изначальная поломка, которая привела к такому состоянию, — система у нас вошла в такой порочный круг, в контур положительной обратной связи, и будет поддерживать себя сама в таком плохом состоянии. Самостоятельно она выбраться из такого состояния не может, потому что здесь одно обстоятельство приводит к другому. В общем, всё довольно плохо.
Давайте ещё раз посмотрим на графики и отметим такую деталь, что система, когда перешла в это сломанное состояние, она хоть и пытается обрабатывать запросы, но КПД — процент полезных действий, которые система выполняет, — довольно низкий. Сходу на самом деле не очень понятно, почему так происходит, потому что кажется, что до поломки бэкенд успешно обрабатывал 200 RPS нагрузки, и после устранения триггера он в целом мог бы продолжать то же самое делать, но он почему-то этого не делает.
Ответ на этот вопрос в следующем. Когда система у нас не перегружена, у нас запросы попадают на бэкенд, и так как ресурсов хватает, они сразу могут браться в обработку, запрос обрабатывается, отдаётся обратно на клиент. Когда система у нас находится в состоянии перегруза, запрос попадает в систему, но свободных ресурсов для обработки этого запроса нет. Что происходит? Запросы встают в очередь. Если система довольно сильно перегружена, запросы в очереди могут находиться достаточно длительное время, и суммарное время на обработку запроса — это время нахождения в очереди плюс время обработки бэкендом на выполнение какой-то логики, — это время сильно вырастает. Клиент не дожидается этих ответов, и вот этот ответ, который сгенерировал бэкенд, он уже никому не нужен, клиент его не ждёт. Запрос — это работа, выполненная вхолостую. Бэкенд старается переварить ту нагрузку, которая на него свалилась, но делает это достаточно неэффективным способом.
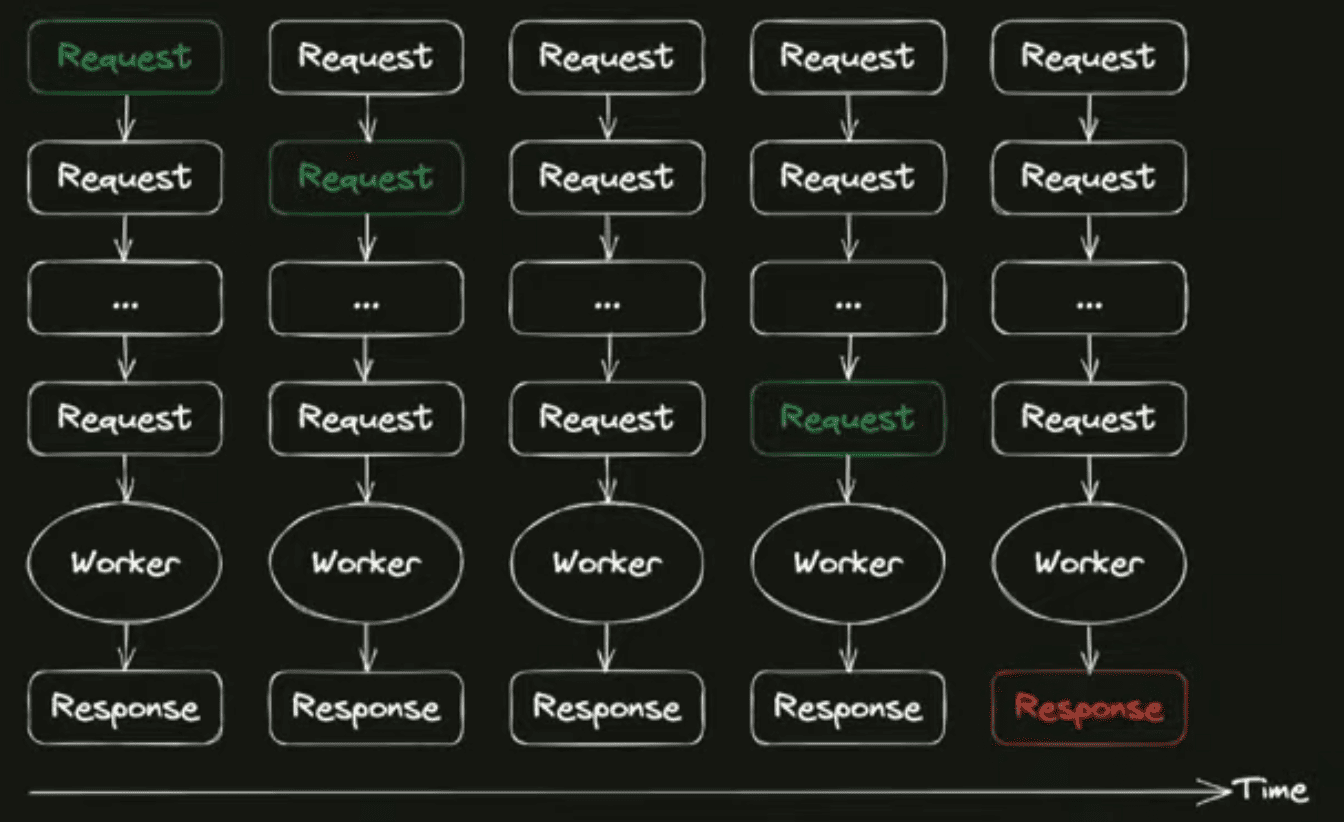
Тут тоже возникает такой вопрос: неужели теперь каждое случайное событие, которое там нам не подконтрольно — какие-то проблемы в сети, или может быть диски в базе данных сломались, в общем, тайминги сильно выросли, — неужели каждое такое событие будет приводить к таким катастрофическим последствиям?
На самом деле нет. Можно сказать, что нам не повезло в нашем изначальном примере, и всё могло пойти по более оптимистичному сценарию.
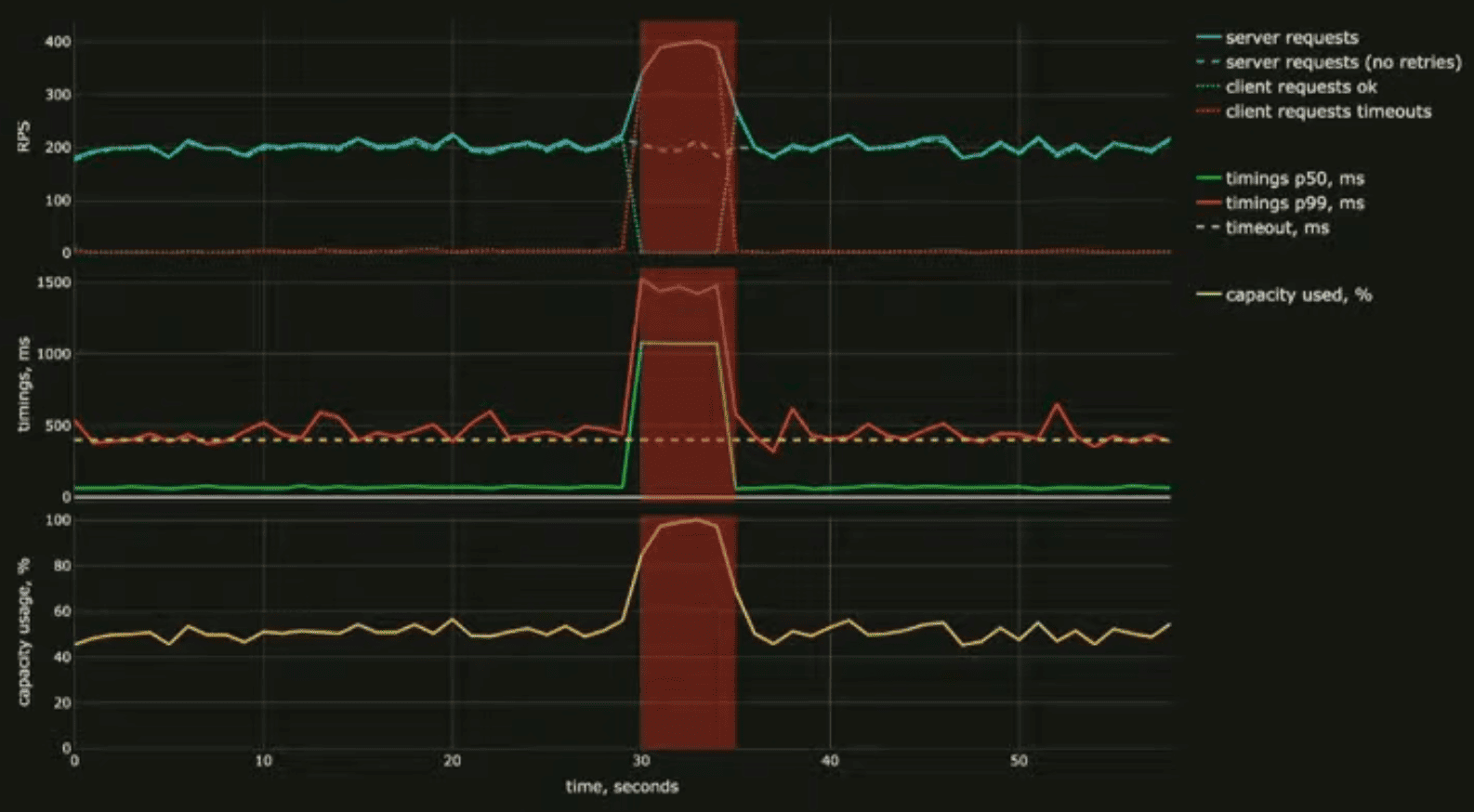
Предположим, что у нас нагрузка на систему была в два раза меньше. Допустим, у нас было не пиковое время, когда на сервис больше всего нагрузки, а какое-то другое время дня или время года, в зависимости от того, какая сезонность у вашего сервиса. Если бы нагрузки было в два раза меньше — 100 RPS вместо 200 RPS, — то даже при таком же триггере, при сетевой недоступности, видно, что система способна вернуться в стабильное состояние. Здесь система не упёрлась в лимит своих ресурсом. Да, были кратковременные проблемы, но после этого перевеварила всплеск нагрузки и вернулась в стабильное состояние, всё хорошо.
Или же в нашей фиче ретраев мы могли сделать не две дополнительные попытки, а всего одну попытку. Тогда бы усиление нагрузки из-за ретраев было бы не таким большим, и в целом система тоже может с таким всплеском нагрузки справиться и вернуться в стабильное состояние.
С примером всё. Давайте попробуем теперь понять на примере, что же произошло, и как это распространяется на какие-то другие случаи. Собственно, есть более системный подход к изучению metastable failure state. Были проанализированы разные ситуации, как вообще система эволюционирует, как она попадает в такое болезненное состояние.
Упрощённо можно сказать, что система может быть в каком-то устойчивом состоянии , в котором триггеры ей не страшны. Но при, например, росте нагрузки или при совпадении других факторов, ваша система переходит в уязвимое состояние, уже из которого про появлении триггера система может свалиться в метастабильное состояние, и дальше есть какой-то самоподдерживающийся механизм, который мешает системе оттуда выбраться, и с этим уже довольно тяжело что-то сделать.
Сама система выбраться не может, здесь уже требуются какие-то серьёзные ручные вмешательства: полностью снимать нагрузку, рестарт системы, какие-то такие вещи. То есть пунктирная стрелочка — это уже как бы здесь требуются активные действия там от команды эксплуатации или разработки, чтобы систему вернуть к жизни.
Триггеры часто называют "чёрными лебедями", то есть это события, которые довольно сложно предсказать, когда и в какой форме они случатся.
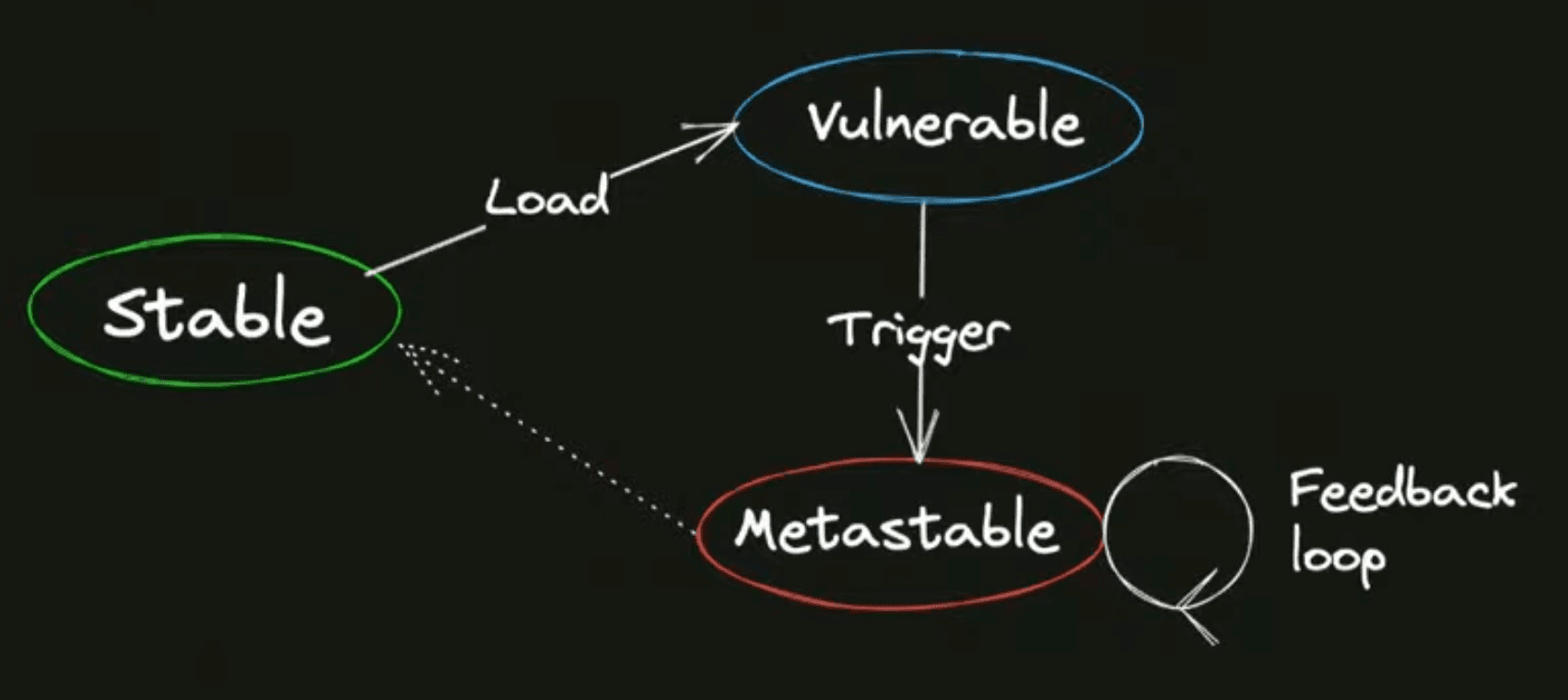
Давайте зафиксируем в виде пунктов то, что мы увидели на нашем первом примере:
1Триггер может прийти и дальше уйти, но при этом система остаётся в метастабильном состоянии и сама по себе не чинится. Тут на самом деле ключевая мысль заключается в том, что проблемой был не триггер, то есть проблема находится в самой системе, которая позволяет триггерам ломать себя подобным образом.
2Система, которая входит в metastable состояние, имеет довольно низкий КПД обработки. То есть перевариванию всплеска нагрузки мешает то, что обработка под нагрузкой запросов устроена так, что она часто бывает довольно бесполезная, и переварить накопившуюся нагрузку не удаётся.
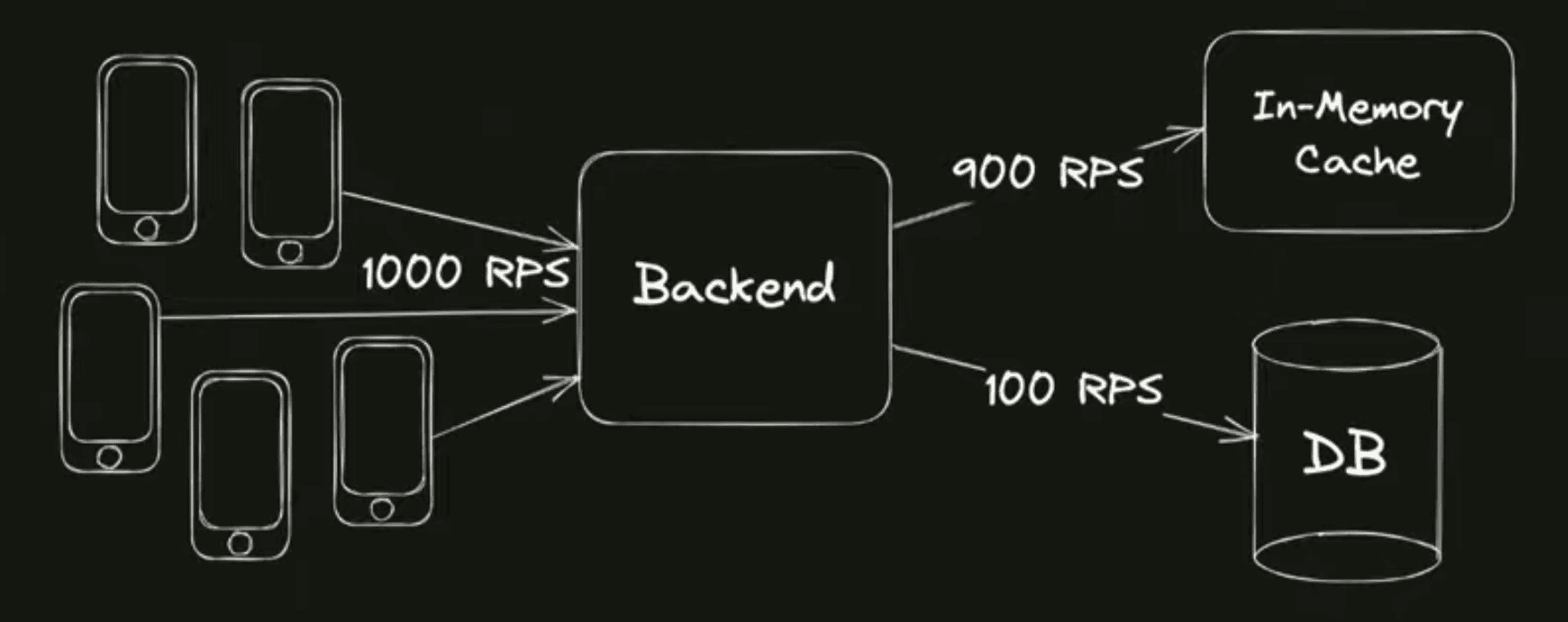
Посмотрим ещё на один пример. Снова примерно тот же сервис: у нас есть мобильные клиенты, есть бэкенд, а это могут быть какие-то другие запросы, но смысл такой, что у нас есть 1'000 RPS входящей нагрузки. Как обрабатываются запросы? Сначала мы проверяем наличие данных в каком-то локальном кэше, который в памяти находится. Если там данных хватает, мы можем сразу обработать запрос и вернуть ответ клиенту. Если же в кэше данных нет, то мы идём в базу данных за данными, которые в базе данных уже точно есть.
Кэш — классная оптимизация, у нас довольно хороший hit ratio 90%, и мы вот такую высокую нагрузку в такой архитектуре вытягиваем.
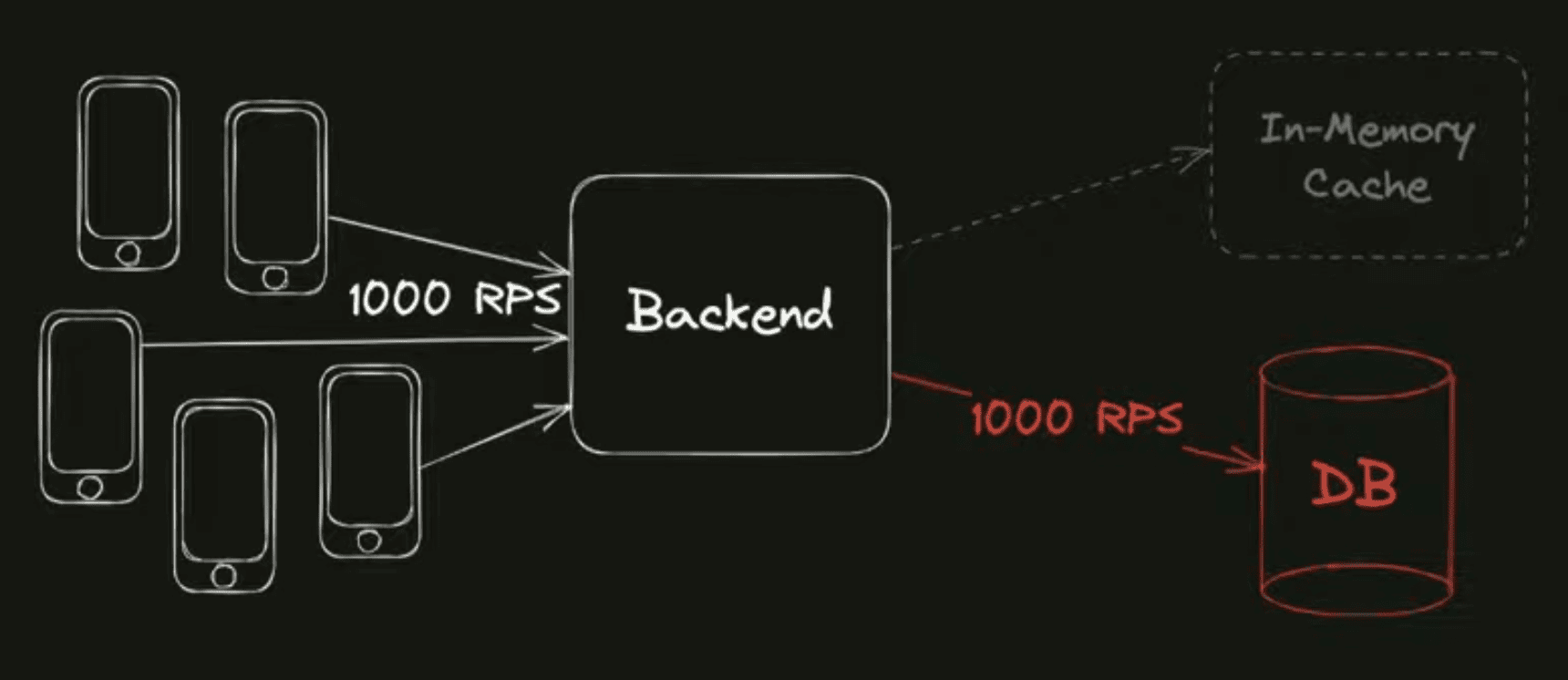
Что может произойти? Так как кэш находится в памяти, а память — волатильное хранение данных, ваш процесс может крэшнуться, перезапуститься, и ваш кэш, который был в памяти, будет потерян. Что в таком случае происходит? Так как ваш кэш холодный при перезапуске, данных там нет, то вам приходится на каждый входящий запрос ходить в базу данных. Если раньше мы ходили с нагрузкой в 100 RPS, сейчас мы ходим с нагрузкой в 1'000 RPS — десятикратное усиление нагрузки на базу.
Если в вашей базе был запас ресурсов примерно десятикратный, то возможно она эту нагрузку вывезет. Если запаса не было, то снова система может войти в metastable состояние, из которого уже будет не так просто систему вывести — снятием нагрузки, или если вы можете быстро автомасштабировать, закинуть ресурсы в базу, в принципе тоже может помочь.
Ещё один пример. Если до этого у нас основные проблемы возникали из-за того, что нагрузки внезапно становилось больше, то есть из-за ретраев или вот как здесь у нас изменился флоу обработки запросов — раньше мы через кэш их обрабатывали, теперь все запросы вынуждены обрабатывать через базу данных, и на базу появилась амплификация нагрузки.
Банально у вас может быть запросов не увеличится, но стоимость обработки одного запроса может варьироваться. Вот во многих языках есть механизм исключений, но он довольно дорогой. Если вы 90% запросов обрабатывается в happy path, исключения не нужны, то всё довольно дёшево. Если что-то происходит, и вы вынуждены практически в большинстве запросов использовать исключения, стоимость обработки запросов сильно вырастает, вы снова можете упираться в какие-то системные ресурсы, и обслуживание запросов деградирует, и системе будет сложнее справляться с обработкой запросов.
Здесь делаем третий вывод: характерной особенностью систем, которые входят в metastable состояние, является то, что в системах может быть заложено так называемое бимодальное поведение. То есть ваша система может функционировать при одинаковой нагрузке в разных режимах. И что самое важное, в разных этих режимах стоимость обработки входящей нагрузки разная. Как правило, она выше в каком-то режиме, в котором система обычно не работает.
Есть очень хорошая статья про принцип constant work, про бимодальное поведение.
И ещё одна мысль про metastable: на наших примерах этого не видно, потому что они довольно просты для того, чтобы было легче объяснить, но вообще в сложных распределённых системах, где много компонентов, вот это metastable состояние, можно сказать, заразное и может распространяться по всей системе. То есть у вас сломалась сначала какая-то одна часть системы, там случилась амплификация нагрузки, и она распространяется дальше по вашей сложной системе, и тем самым складываются другие компоненты системы. То есть система может каскадно входить в metastable состояние.
Переходим к заключительной части: какие у нас есть подходы к тому, чтобы не допускать вхождение в metastable состояние, и как мы с этим боремся.
Мы видели на примерах, что система в состоянии обслуживания запроса в системе деградирует из-за того, что мы упираемся в какие-то ресурсы. То есть не хватает CPU, может пропускной способности диска. Поэтому лучше заблаговременно следить за тем, чтобы в системе ресурсов хватало даже при каких-то всплесках нагрузки.
Как мы это делаем? У нас есть специальная система, которая анализирует утилизацию ресурсов микросервисами и базами данных, с которыми эти микросервисы работают, и там можно заблаговременно узнать, что в каком-то месте системы есть узкое горлышко, что ресурсов не хватает на предполагаемый рост нагрузки в два или во сколько-то раз, придёт об этом уведомление ответственной команде, и она может расширить ресурсы системы заранее, и всё будет хорошо.
Также в моменте, когда у вас уже всё-таки кончились ресурсы и заранее вы их не добавили, важно знать, в каком месте их прямо сейчас не хватает. Потому что каскадно у вас может сложная система сложиться, ресурсов будет не хватать в довольно большом числе компонентов системы, и важно, чтобы ответственные команды получали об этом оперативно алерты и как-то на это реагировали.
Что мы ещё делаем для того, чтобы проверить, какой у системы есть запас прочности, сколько она может дополнительной нагрузки переварить? У нас есть регулярные учения. Раз в несколько недель мы снимаем полностью нагрузку с одного из дата-центров, и оставшиеся дата-центры вытягивают всю ту нагрузку, которая есть на входе. Это один из способов, который тоже позволяет проверить, что у вас хватает процессора, пулов соединений до базы, каких-то сетевых гарантий, что действительно система рассчитана на рост нагрузки.
Многие пишут, что автоскейлинг тоже хорошее средство. Если ваша инфраструктура позволяет достаточно оперативно докинуть ресурсов в нужное место, отмасштабироваться, то это может сильно сгладить эффект от амплификации нагрузки и узкое горлышко закрыть. У нас пока автоскейлинга нет, но мы подумываем об этом.
Проблема с докидыванием ресурсов обычно заключается в том, что это тяжело сделать быстро, особенно в момент инцидента. Где-то инфраструктура позволяет, где-то нет. И вопрос возникает: а что же делать в моменте, если вот докинуть ресурсов нет? Например, уже базу данных нельзя вертикально отмасштабировать, только шардирование — в моменте вы это вряд ли сделаете.
Альтернатива докидыванию ресурсов — это снятие избыточной нагрузки с системы. Многие наши микросервисы написаны на фреймворке userver, и в нём есть встроенный механизм Congestion control, который понимает, что система перегружена, и лишнюю нагрузку просто откидывает на входе, то есть не обрабатывает запросы, которые создают чрезмерную нагрузку. Очень классный механизм, всё здорово, но у него есть минус: он защищает только сам сервис, но не защищает, скажем, его зависимости, другие сервисы, которые не написаны на userver, или базу данных, которые за сервисами расположены.
Что в таком случае делать? Мы используем активно RPS-лимитеры. То есть мы в точках входа указываем, какую максимальную нагрузку сервис с текущим количеством ресурсов может вытянуть, устанавливаем лимиты, поддерживаем их актуальными. И если нагрузка превышает лимит, то она тоже на входе отбрасывается, не заставляя бэкенд делать какую-то избыточную работу и не перегружая его.
Также мы видели на примерах, что ретраи — это довольно опасная вещь. Они нам помогают чинить какие-то редкие ошибки, улучшать пользовательский опыт, но по факту, когда всё становится плохо, ретраи создают очень много избыточной нагрузки — мы в первом примере видели, что нагрузка возрастает троекратно, — и как будто бы это тот момент, когда на самом деле ретраи не нужны. Для этого у нас есть механизмы отключения ретраев, которые срабатывают как раз при большом числе ошибок. В целом эта тема довольно интересная, и тут снова есть ссылка на разные статьи, которые обсуждают подходы, сложность реализации этих подходов на клиентах, на бэкенде, как правильно отключать ретраи или бюджетировать ретраи. Очень советую почитать, классные статьи.
Ещё важно уметь снимать нагрузку с системы целиком где-то в точке входа и плавно возвращать. Почему нужно возвращать плавно? Если у вас система сломалась, вы, скажем, с неё полностью сняли нагрузку, и если вы резко на неё вернёте нагрузку, возможно она не справится с этим всплеском нагрузки. Почему? Потому что в холодной системе не прогреты кэши, не прогреты соединения до базы, и на старте она будет обрабатывать запросы достаточно долго. Когда мы долго обрабатываем запросы, у нас большая нагрузка, это всё снова может привести к тому состоянию, из которого мы пытались выбраться.
Важно эти инструменты иметь готовыми заранее, потому что в моменте инцидента, если этих инструментов нет, приходится делать что-то, искать в интернете, какой конфиг nginx написать, чтобы нагрузку плавно возвращать, и это делать в спешк, под стрессом довольно тяжело.
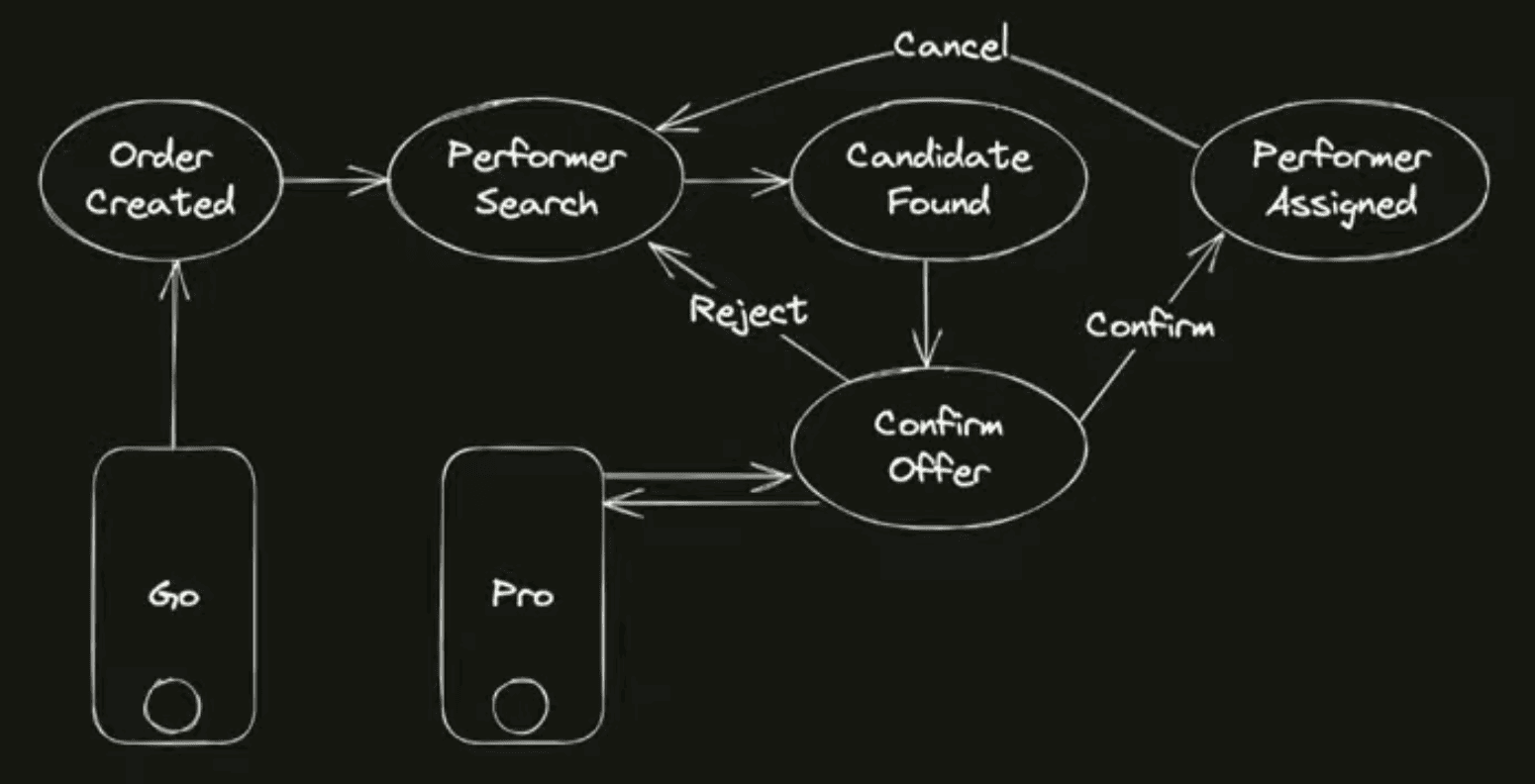
Посмотрим теперь на заказы Такси. То есть до этого мы говорили про синхронные запросы, условно HTTP API, они довольно короткоживущие. С заказами Такси всё немного посложнее.
Как устроен заказ Такси? Пользователь создаёт заказ, он попадает в систему назначения, там с ним что-то происходит, предлагается водителю его выполнить. Ключевое отличие заказов от синхронных запросов:
1Они долгоживущие. Время их жизни сильно дольше, чем время жизни запроса.
2Если запрос вы можете просто отбросить, пользователь увидит какую-то ошибку в приложении, с заказами это сделать довольно сложно, потому что заказ должен оказаться в каком-то терминальном статусе. Вот вы не можете его бросить и выкинуть, перестать обрабатывать. Возможно, вы уже сделали какой-то прехолд денег с пользователя, и вам естественно нужно их вернуть, потому что заказ, например, отменён и не обработан. Поэтому выкидывать заказы из обработки просто так не получится, всё равно их нужно в конечном итоге в какое-то терминальное состояние довести.
В силу специфики заказов важно ещё понимать такую вещь. До этого мы говорили про RPS-лимиты, мы измеряли нагрузку в единицах измерения "сколько запросов приходит в единицу времени", в секунду, например. Но важно понимать не только какой входящей нагрузки, но и сколько у вас одновременно запросов находится в системе в обработке.
Чтобы это посчитать, прикинуть в среднем, есть простая формула — закон Литтла, — которая говорит, что чтобы посчитать ваш concurrency, нужно умножить входящий рейт запросов на среднее время нахождения запроса в системе. Если у вас 100 RPS нагрузки и 100 миллисекунд запрос обрабатывается, у вас одномоментно где-то 10 запросов находится в системе обработки. Если тайминги обработки увеличиваются, то и число запросов в системе у вас тоже увеличивается, хотя RPS не вырос.
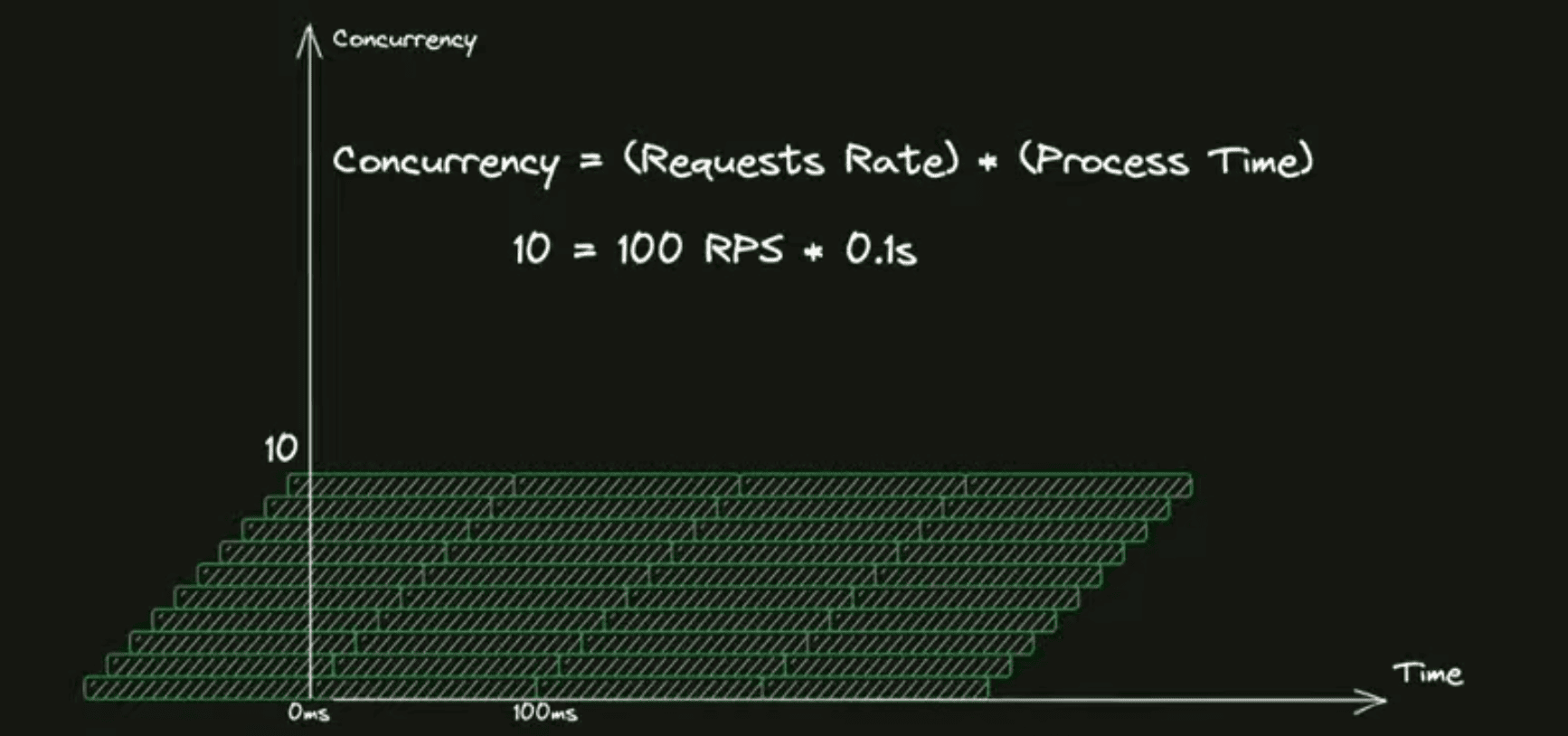
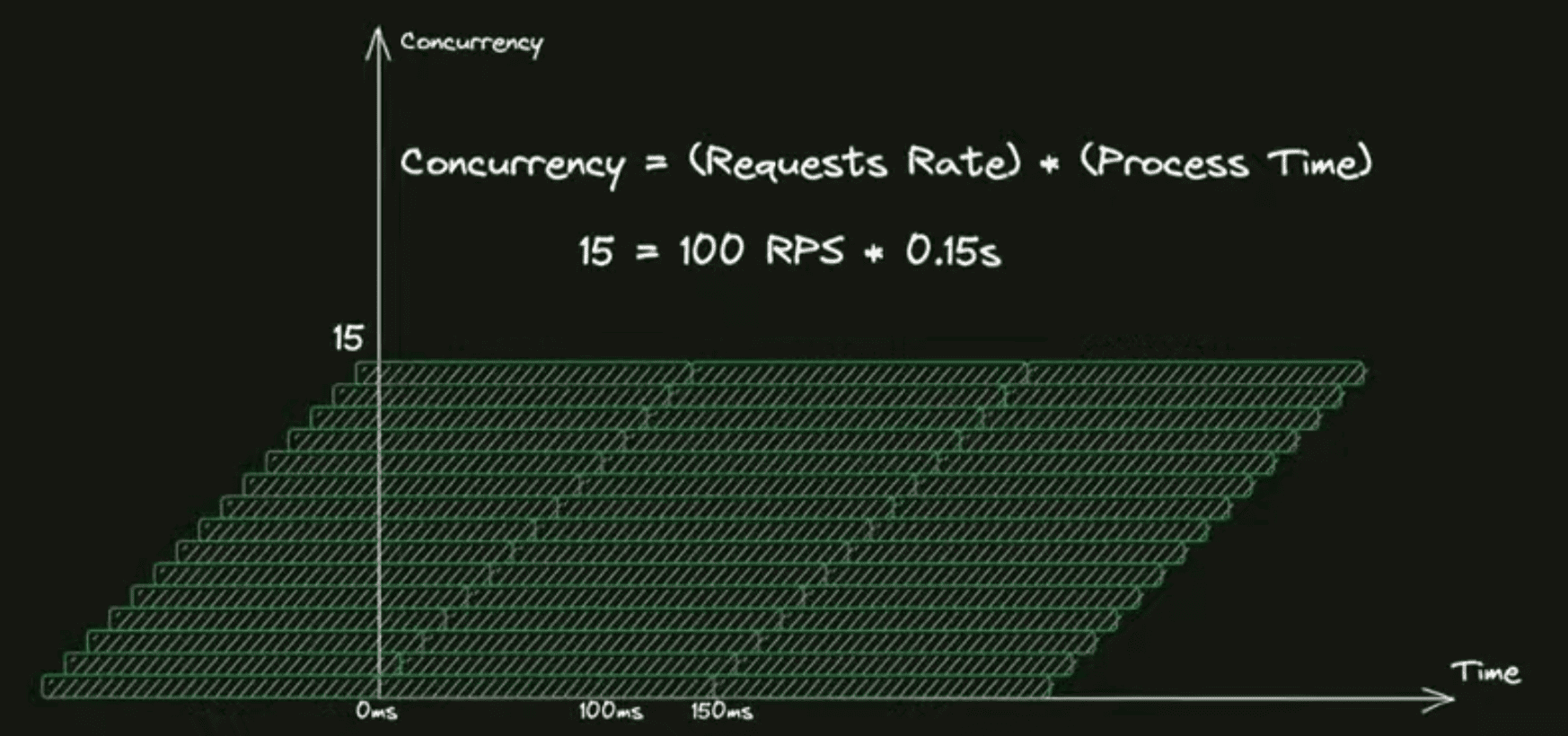
Почему это важно для заказов? Хотя изначально всё было хорошо, вы где-то за 30 секунд обрабатывали назначение заказа в такси, потом что-то сломалось в каком-то месте, деградация произошла, и назначение стало работать дольше, и с 30 секунд у вас время назначения выросло в шесть раз, например, до 3 минут.
Мы видим, что число заказов в системе, одновременно находящихся, тоже выросло в шесть раз, при том что скорость поступления новых заказов в систему не изменилась, это видно по вертикальным зелёным линиям. Получается, что у нас заказов в системе больше, каждый из заказов, который всё ещё в обработке, создаёт нагрузку на микросервисы, которые пытаются на заказ найти исполнителя. Таким образом, у нас амплификация получилась без изменения входящей нагрузки в виде рейта заказов.
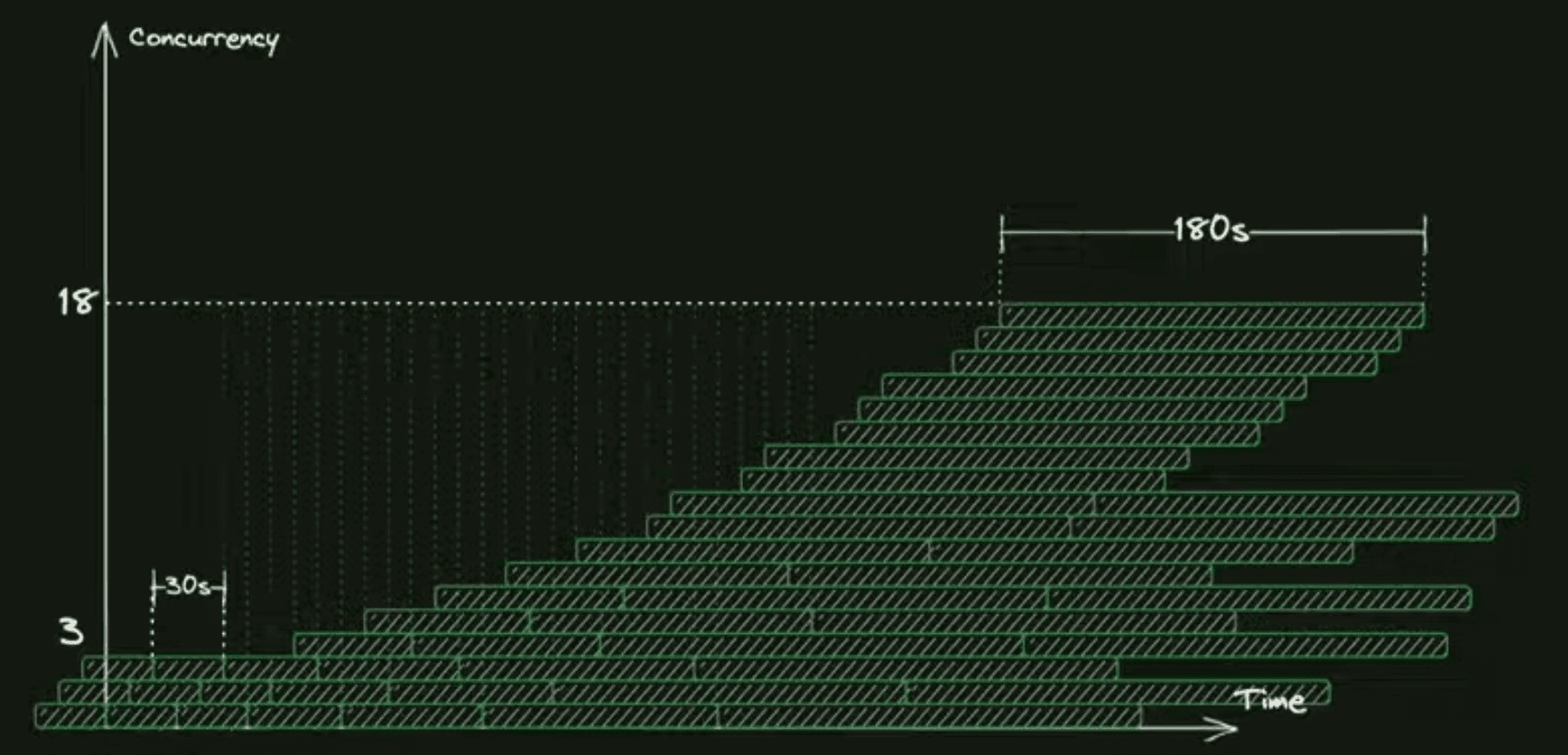
Какой вывод? То есть RPS-лимитов бывает недостаточно, потому что важно также следить в некоторых случаях за тем, сколько у вас прямо сейчас в моменте находится заказов в системе в обработке. Поэтому у нас есть помимо PRS-лимитов concurrency-лимиты на заказы, которые находятся в системе в обработке.
То, что мы уже видели: если при обработке запросы выстраиваются в очередь, может получиться так, что мы обрабатываем запросы, которые уже никому не нужны. С заказами Такси та же самая история: если мы будем заказ долго держать в очереди в перегруженной системе, начнём ему искать исполнителя достаточно поздно, возможно, пользователь уже и не ждёт, что на заказ будет найден исполнитель, мы будем делать бесполезную работу.
Что с этим делать? В моменты перегруза можно менять политику обработки очереди заказов и брать сначала самые свежие заказы, потому что вероятность того, что они ещё нужны пользователям, она сильно выше, чем в заказах, которые были созданы давно. Там, скорее всего, пользователь уже расстроился и ушёл.
Ещё один способ, как можно упереться в лимиты очереди. Допустим, у нас всё было хорошо, но потом в каком-то проценте заказов на какой-то фиче, например, у нас сломалась обработка заказов. Но, как я говорил, что заказы просто так отбросить нельзя, они остаются в очереди, мы пытаемся их обработать и обработать, эти заказы никуда не деваются. Поступают новые заказы с этой сломанной фичей, их доля в общем потоке заказов растёт, и в какой-то момент, когда мы упираемся, скажем, в concurrency-лимиты очереди, они начинают давить уже на не сломанные заказы, мешать им выполняться, выедать их квоту.
Что с этим можно делать? Опять же в моменты перегруза у нас включается деприоритизация таких сломанных заказов. Мы уже не ретраим их, а в первую очередь отдаём предпочтение заказам, которые ещё не сломаны.
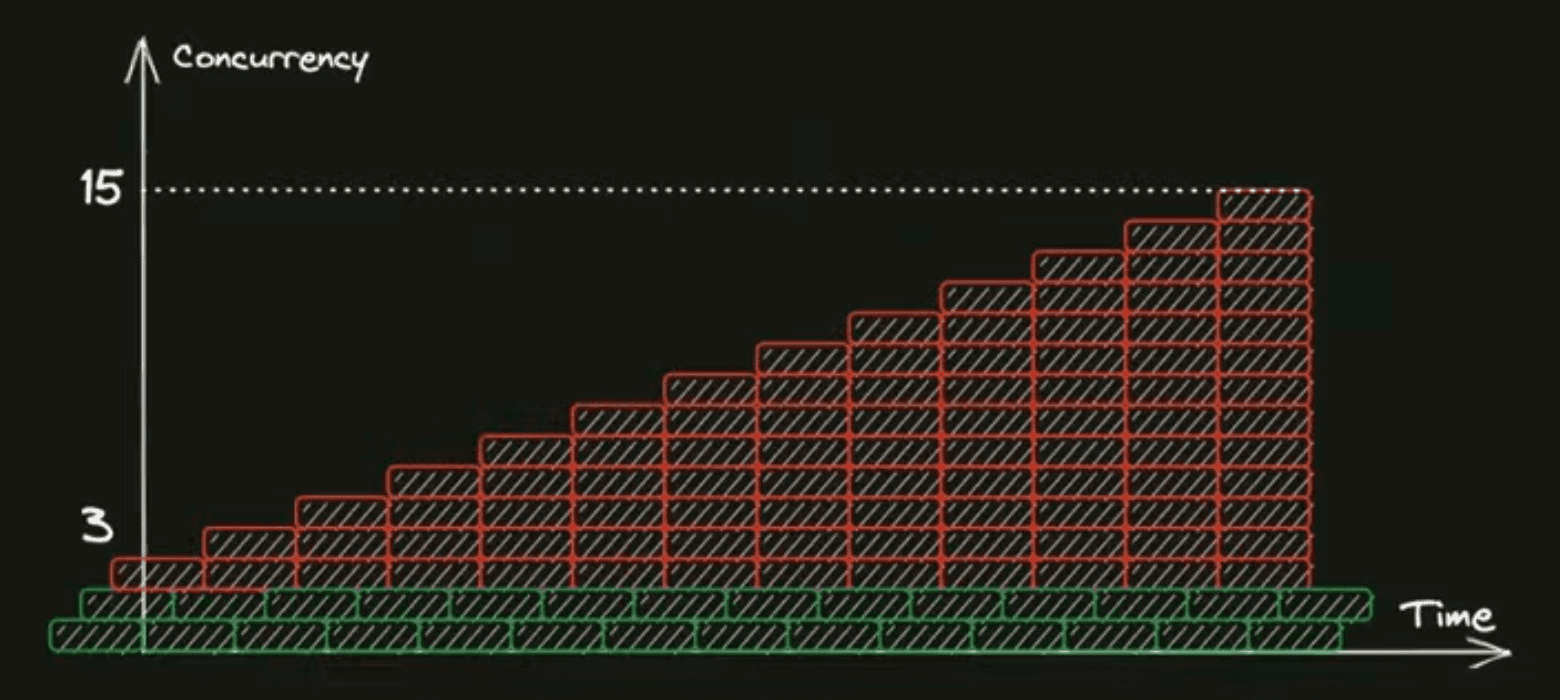
Ещё один подход, который нам довольно сильно помогает. В моменты, когда система перегружена, нужно где-то достать дополнительные ресурсы. Один из способов это сделать — это отключить некритичный функционал. А при этом отключение этого функционала освободит ресурсы на микросервисах, и эти ресурсы можно будет использовать для критичного функционала. Важно, чтобы это был бы какой-то простой конфиг, который говорит: "Всё, мы в режиме деградации", и по большому числу микросервисов отключаются некритичные фичи, и мы получаем какой-то запас ресурсов, который нам позволит там разгрести накопившийся бэклог задач.
Подытожим, что нужно делать, чтобы не входить в MFS или выбираться оттуда:
1Избегайте антипаттернов, приводящих к metastable, которые делают вашу систему уязвимой. То есть аккуратно с ретраями, с кэшами, и в целом, если общими словами говорить, то есть нужно следить за принципом constant work, и на ревью архитектуры подсвечивать опасные моменты, которые системе могут навредить.
2Если уж всё-таки система вошла в metastable состояние, заранее подготовьте инструменты, которые вам позволят оперативно сбросить нагрузку с системы, потому что это сильно быстрее, чем доливать ресурсы. А срезание нагрузки — это немногое, что работает, когда система уже в metastable состоянии.
3В перегруженном состоянии часто бывает полезно изменить политики обработки, например, FIFO заменить на LIFO в очередях, или деприоритизировать сломанные задачи, которые и так не выполняются.
Слушатель: Пока рассказывали, там на одном слайде показывали, что вы постоянно ведёте аналитику вот этих событий, когда там metastable случились, и потом на основании этого всего у вас какие-то там разборы бывают. У меня вопрос: вот эту аналитику, которая у вас от сервисов, предшествующая этим событиям, рассматривают люди или это какой-то уже шаг дальше в сторону аналитики с точки зрения машинного обучения или ещё что-то? Как выявить потенциальные случаи вот этого metastable? Если использовать нагрузочное тестирование, мы можем протестировать потенциальную мощность какого-то сервиса или кучи микросервисов, но не факт, что они войдут в это состояние.
И второй вопрос — вы какие-то триггеры выявили, к примеру, чёрная пятница, либо ещё что-то. Есть ли у вас какой-то справочник этих триггеров, которые вы в дальнейшем используете в тестировании, делитесь ли вы ими публично? Всегда ли эти триггеры связаны исключительно с запросами, или это может быть, к примеру, SSD диски при заполнении начинают хуже обрабатывать базу, и если машинное обучение используете, оно скажет, что пока вы бэкапы не сделали, у вас к концу месяца тормозит всё, а потом сделали бэкапы, место освободили, и опять всё восстановилось, вроде и запросов не было, и ещё чего-то.
Алексей: По поводу первого вопроса, наверное, начну со второй части: машинное обучение мы пока не подключаем к анализу инцидентов, хотя, возможно, это хорошая идея. Пока что основной способ разбора — руками. У нас есть команда, которая занимается надёжностью. Крупные сложные поломки достаточно долго разбираются, проводим ретроспективу. Чинить можно не только там само вхождение в metastable, но и средства узнавания о том, что проблема есть заранее — мониторинги, алерты. В момент инцидента важно понять, где узкое бутылочное горлышко. Не должно быть слепых пятен, мы должны понимать довольно быстро, откуда нужно снимать нагрузку, чтобы бэклог рассосался.
Мы формируем экшн айтемы, причём мы стараемся, чтобы они были обобщаемые. Сломался один сервис => досыпать туда ресурсов — это не обобщаемый экшн айтем. Что нужно сделать? Нужно, во-первых, однократно проанализировать все сервисы, а лучше создать какой-то новый алерт, новый мониторинг на то, чтобы в автоматическом режиме, может быть, сразу формировать драфты на то, чтобы систему расширить. То есть, скорее, в ручном режиме, команда собирается и формирует наши действия: как там починить текущие уязвимости и как в будущем их не допустить. Такой ручной процесс.
По поводу второго вопроса, про справочник триггеров. Как я говорил, на самом деле, наше отношение, по крайней мере моё точно, в том, что триггеры не так важны. Во-первых, их сложно предсказать, и само по себе плохо не то, что триггер случился, а то, что система позволила триггеру перевести себя в плохое состояние. Какие-то триггеры очень тяжело предсказать, например, есть кабель между дата-центрами, его может при строительных работах экскаватор перерубить. Как это предсказать и что на этот случай делать? Там точно будет какая-то деградация. Или с дисками: предсказать, когда вылетит диск в RAID-массиве, может и можно, но защититься от любой непредвиденной ситуации довольно тяжело. Важно уметь при том, что она происходит, не позволять систему перегрузить и не входить в болезненное состояние.
Слушатель: Как сложность метастабильных состояний и отказов Такси-сервисов может повлиять на принятие решений в реальном времени и какие стратегии могут быть использованы для улучшения реакции в таких ситуациях?
Алексей: Ключевая сложность, когда я в целом думал про эту тему — то, что оно само не чинится, и пока там команда разработки, эксплуатации что-то не сделает, оно будет сломано. Чтобы быстро починить, во-первых, нужны инструменты observability, то есть мы должны понимать, в каком месте оно сломано, не должно быть каких-то мест, которые не покрыты графиками, подробными логами, чтобы можно было диагностировать инцидент. Часть проблем можно починить откатом релиза, не разбираясь в проблемах. Например, увидели, что поменяли конфиг, дальше не глядя откатили. Иногда это работает, иногда нет. Когда это не работает, нужно в моменте пытаться раскопать причину проблем.
Ведущий: Здесь отчасти ещё вопрос про то, как понять, что у нас КПД достаточно хороший, что мы не вхолостую работаем?
Алексей: Тут тоже нужно улучшать метрики. Есть есть базовые метрики, и мы там по ним видим, что какие-то запросы обрабатываем, заказы назначаем, но в контексте КПД оказывается, что эти заказы никому были не нужны. Вот здесь нужно улучшать метрики, делать их более сложными и правильными в том смысле, что не засчитывать назначение заказа, если он уже никому не нужен, а пытаться понять, что мы успели назначить вовремя, например, за временем назначения следить. Если оно сильно вырастает, то это уже сигнал к тому, что где-то есть узкое бутылочное горлышко, и нужно это место чинить.
Слушатель: Всё очень круто, когда у тебя есть возможность влиять на продукт, то есть можно прийти к ребятам, сказать: "Чуваки, сделайте пожалуйста, чтобы это работало вот так". У меня, например, эксплуатация, скажем так, вендорская, и у меня петля обратной связи с продуктом достаточно длинная, чтобы они какие-то фиксы вносили. Вот стоит ли овчинка выделки, можно ли всё это сделать чисто инфраструктурно, или это будет очень дорого с вашей точки зрения? Система достаточно большая, нагрузка, скажем так, несравнима с вашей.
Алексей: Часть вещей делаются на инфраструктурном уровне. Например, автоматическое включение ретраев. Ни бизнесу, ни пользователям не важно знать, как под капотом устроены ретраи. Мы понимаем, что у нас два режима: когда всё хорошо, и ретраи в целом помогают, и когда всё плохо, нужно по статистике ошибок это понять и автоматически их отключить, например. То есть это чисто инфраструктурное решение. Но бывают решения, которые нам приходится согласовывать с бизнесом, например, деградация функционала. Мы можем ухудшить качество сервиса, время подачи может рассчитываться не так качественно, но мы за счёт этого сэкономи ресурсы и пустим их на то, чтобы обслуживать самое ценное в продукте. Я не знаю, насколько это доступно в вендорской разработке, но диалог с бизнесом часто помогает. Он тоже заинтересован в том, чтобы кор часть продукта тоже работала, даже если какие-то фичи отвалились.
Слушатель: Диалог с бизнесом есть, но он очень длинный. А делать что-то надо уже сейчас. Всё, что мог со стороны инфраструктуры, я уже сделал. У меня вопрос в том, стоит ли пытаться закрыть вообще всё своими силами, но это будет очень дорого, как мне кажется.
Алексей: Всегда можно посмотреть на опыт других компаний. Ряд компаний открыто делится разбором инцидентов, можно почитать постмортемы, стратегии, которые они рекомендуют. Возможно, даже пишут и про то, как с бизнесом договориваться. Без диалога, кажется, будет не очень просто. У нас это получается, так как продукт собственный, и таких проблем обычно не возникает.